
Technology deep-dive
LLM-assisted OCSF mapping: what the migration tax actually looks like.
OCSF (Open Cybersecurity Schema Framework) is one of four foundational open standards I name when describing the security lakehouse, alongside Apache Arrow for in-memory layout, Apache Iceberg for the table format, and Sigma for detection-rule portability. The blocker for OCSF adoption at the source is almost never the spec itself, because what actually stalls teams is the translation tax of turning vendor-shaped logs (Zeek, CloudTrail, Okta, EDR vendor X) into OCSF-shaped events. This piece is about what that tax looks like when you put a modern LLM against it, and where the honest limits of that claim sit.
Reading time: about 20 minutes. Evidence tier: B at best. The headline observation comes from my own time-tracking across 12 OCSF mapping projects (2024–2025). Call it N=12 enterprise study, with all the small-sample caveats that label implies. I flag where I'm extrapolating, where the numbers are directional rather than measured, and where the LLM-version-pinning question matters.
Sample-size disclosure first
N=12 is small. Here's what that means.
Before any of the numbers below, the honest framing. The "12 enterprise study" is my own time-tracking across 12 OCSF mapping projects I worked on or observed closely between 2024 and 2025. It is not a randomized sample. Selection bias is real: these were projects where someone (often me) decided LLM-assisted mapping was worth trying, which skews toward sources with reasonable documentation and toward teams already comfortable with AI-assisted development workflows.
Three specific limits to keep in mind throughout. First, sample size: N=12 cannot resolve effect sizes finer than roughly 25–30 percent. Any "6–9× speedup" claim has a confidence interval wide enough to drive a truck through, and I treat it as directional. Second, time horizon. The LLM ecosystem moves faster than the study window. Numbers measured against GPT-4 (early 2024) and Claude Sonnet 3.5 (mid-2024) may already be conservative against Claude Sonnet 4.5 or GPT-5; they may also be wrong in subtle ways as model behavior shifts. Third, source-schema bias. The 12 projects skew toward Zeek, AWS CloudTrail, Okta, and Office 365. Custom application logs and exotic vendor formats were underrepresented, which is exactly where the LLM is most likely to struggle.
With those caveats stated up front, here's the observation that motivated writing this down: in the mapping projects I tracked, LLM-assisted OCSF mapping appears to take roughly 15–25 minutes per log source against a manual baseline of 2–4 hours, with field-mapping accuracy near 95 percent after a domain-expert review pass, and the rest of the essay unpacks where that claim does and doesn't hold.
Why OCSF is the foundational standard
The schema layer of the four-pillar stack.
When I describe the security lakehouse to architects, I name four foundational open standards: Apache Arrow at the in-memory layer, Apache Iceberg at the on-disk table-format layer, Sigma at the detection layer, and OCSF at the schema layer. Each pillar is interchangeable in theory but does real work in practice, so if you pull any one out the composability argument collapses.
OCSF specifies what a "Network Activity" event or an "Authentication" event looks like in canonical form: which fields exist, what their types are, what semantic meaning they carry. AWS Security Lake normalizes to OCSF on ingest, Splunk has an OCSF app, and the OCSF community ships schema updates quarterly, so the standard is real, the adoption curve is steep, and the political question of whether OCSF "wins" against ECS (Elastic Common Schema) and CIM (Splunk's Common Information Model) looks increasingly settled in OCSF's direction for new lakehouse deployments, though I'd want another two years of evidence before calling that definitive.
The blocker for OCSF adoption at the source is the schema-translation tax, because your firewall vendor ships logs in their format, Zeek ships logs in Zeek format, and your EDR ships logs in EDR-vendor-X format. Getting any of that into OCSF-shaped events requires a per-source mapping: field by field, with semantic alignment checks, type conversions, and validation. Done by hand, that's two to four hours per source. For an enterprise with 50 log sources, that's 100–200 hours of skilled-engineer time before anyone can run an OCSF-shaped detection query.
This tax determines whether OCSF stays a vendor talking point or becomes a deployed standard, because the migration cost is what stalls adoption and that cost is dominated by the schema-translation step, so if LLMs shrink it meaningfully the adoption math changes, which is why the question matters beyond the immediate engineering exercise.
The three approaches
Manual, LLM-assisted, vendor-automated.
There are three live approaches to getting a log source into OCSF shape, and the live question for any architect is which mix sits in front of which source. I'd argue most enterprise OCSF deployments end up using all three in the same pipeline, with the ratios driven by source variety.
1. Manual mapping
Read the source schema, read the OCSF spec, write a field-mapping table, implement the transformation in Python or SQL or Power Query, test against sample data, peer review. Across the 12 projects I tracked, careful manual work landed in the 2–4 hour range per source, with the lower end for well-documented sources (CloudTrail, VPC Flow) and the upper end for sources with 30+ fields or unusual semantics (Zeek protocols, custom application logs).
The manual approach has the strength that every mapping decision is human-reviewable, which matters for compliance contexts where black-box transformations create audit findings, but its disabling weakness is that it doesn't scale, because fifty sources times three hours averages 150 engineer-hours, which in calendar time (factoring in other priorities) usually stretches to eight to twelve weeks, and that's where most enterprises stall on OCSF adoption.
2. LLM-assisted mapping
Feed the source schema (with field descriptions, not just names) to an LLM, prompt it to generate OCSF transformation code, then run a domain-expert review pass over the output. In the 12 projects I tracked, this landed near 15–25 minutes of total human time per source: roughly 5 minutes for the LLM generation step and 10–15 minutes for the semantic-validation review.
The accuracy story is more interesting than the speed story, because raw LLM output without review landed in the 70–80 percent accuracy range, and with domain-expert review catching the obvious errors it reached roughly 95 percent, which is why the review pass is the step you can't skip and the one I walk through in the section below.
3. Vendor-automated mapping
Plug into AWS Security Lake (native OCSF ingestion for CloudTrail, Route 53, VPC Flow), use Splunk's OCSF app, or configure Azure Sentinel's OCSF export, and for standard, common-shape sources the vendor ships the mapping so you pay nothing in engineering time. The catch is twofold: only common sources are covered (custom or legacy logs require a different approach), and the vendor's mapping is opaque. You cannot easily audit how it handles edge cases without running comparative queries against the raw source.
The methodology
What the LLM-assisted workflow actually looks like.
The workflow that produced the 15–25 minute per-source numbers has five steps, and none of them are clever individually, but the combined effect is what makes the approach hold up under domain review.
Step 1: prepare the source schema with descriptions
The single biggest determinant of LLM mapping accuracy across the 12 projects was whether the source
schema included field descriptions, not just names. A column called orig_bytes is
ambiguous on its name alone, but the same column with the description "Bytes sent from originator to
responder (connection initiator to receiver)" is unambiguous, so the LLM gets the direction right.
source_field,data_type,description
ts,timestamp,"Timestamp of connection start (Unix epoch)"
id.orig_h,string,"Originating host IP address (connection initiator)"
id.orig_p,integer,"Originating host port number"
id.resp_h,string,"Responding host IP address (connection receiver)"
id.resp_p,integer,"Responding host port number"
proto,string,"Transport layer protocol (tcp/udp/icmp)"
orig_bytes,integer,"Bytes sent from originator to responder"
resp_bytes,integer,"Bytes sent from responder to originator"Documented schemas (Zeek, OCSF, AWS) come with descriptions out of the box. Custom application logs usually don't, and the prep step then includes asking the source owner to fill them in. That ten-minute conversation may save the LLM from a fifty-percent-wrong directional mapping later.
Step 2: prompt with explicit OCSF class anchoring
The prompt names the target OCSF class (Network Activity 4001, Authentication 3002, DNS Activity 4003, and so on), provides the relevant subset of OCSF fields the LLM should consider, and asks for confidence scores on each mapping. Without the explicit class anchor, the LLM may hallucinate fields that don't exist in the spec or pick a tangentially related OCSF class, whereas with the anchor in place the search space shrinks to something the model can reason about reliably.
You are a cybersecurity data engineer creating OCSF transformations.
Task: Map the following source schema to OCSF Network Activity (class_uid 4001).
Source schema (Zeek conn.log):
[Paste CSV from Step 1]
OCSF Network Activity schema reference:
- class_uid: 4001 (Network Activity)
- time: ISO 8601 timestamp
- src_endpoint.ip: Source IP address
- src_endpoint.port: Source port
- dst_endpoint.ip: Destination IP address
- dst_endpoint.port: Destination port
- connection_info.protocol_num: IANA protocol number (tcp=6, udp=17)
- traffic.bytes_in: Bytes received by destination
- traffic.bytes_out: Bytes sent by destination
Requirements:
1. Generate transformation code (SQL or Power Query M).
2. Include semantic validation comments for ambiguous mappings.
3. Flag each field with a confidence score (High/Medium/Low).The "flag confidence scores" instruction is what makes the review step in Step 4 tractable. A reviewer scanning for Medium and Low confidence fields catches roughly 80 percent of the errors with maybe 20 percent of the time it would take to review every mapping uniformly.
Step 3: the LLM generates transformation code
Across the 12 projects, I used GPT-4 (gpt-4-0125-preview) and Claude Sonnet 3.5 (claude-3-5-sonnet-20240620) in roughly equal numbers, and both produced usable output, with neither better than the other on raw accuracy in a measurable way, since both landed in the 70–80 percent range before review and reached 95 percent after. Version-pinning matters here, because I'd expect Claude Sonnet 4.5, GPT-5, or equivalent 2026-era models to perform at least as well, but I haven't re-run the 12-project benchmark on them, so the specific numbers should be re-validated if you're choosing a model in mid-2026 or later, given that the model landscape moves faster than the study can track.
The output for a Zeek-to-OCSF Network Activity mapping looks roughly like this (Power Query M shown, because it's reviewable in Excel by non-programmers, which is useful in compliance contexts):
let
Source = Csv.Document(File.Contents("conn.log"), [Delimiter="#x09"]),
RenamedSource = Table.RenameColumns(Source,{
{"Column1", "ts"},
{"Column3", "id.orig_h"}, {"Column4", "id.orig_p"},
{"Column5", "id.resp_h"}, {"Column6", "id.resp_p"},
{"Column7", "proto"},
{"Column10", "orig_bytes"}, {"Column11", "resp_bytes"}
}),
AddedClassUID = Table.AddColumn(RenamedSource, "class_uid", each 4001),
AddedTime = Table.AddColumn(AddedClassUID, "time", each
DateTime.ToText(#datetime(1970, 1, 1, 0, 0, 0) + #duration(0, 0, 0, [ts]),
"yyyy-MM-ddTHH:mm:ss.fffZ")
),
// Source endpoint mapping (Confidence: High)
AddedSrcIP = Table.AddColumn(AddedTime, "src_endpoint.ip", each [#"id.orig_h"]),
AddedSrcPort = Table.AddColumn(AddedSrcIP, "src_endpoint.port", each [#"id.orig_p"]),
AddedDstIP = Table.AddColumn(AddedSrcPort, "dst_endpoint.ip", each [#"id.resp_h"]),
AddedDstPort = Table.AddColumn(AddedDstIP, "dst_endpoint.port", each [#"id.resp_p"]),
// Protocol mapping (Confidence: High - IANA standard)
AddedProtocol = Table.AddColumn(AddedDstPort, "connection_info.protocol_num", each
if [proto] = "tcp" then 6
else if [proto] = "udp" then 17
else if [proto] = "icmp" then 1
else null
),
// Traffic mapping (Confidence: Medium - semantic validation required)
// Zeek orig_bytes = bytes FROM originator TO responder
// OCSF traffic.bytes_in = bytes received BY destination
// Therefore: orig_bytes -> bytes_in (PEER REVIEW REQUIRED)
AddedBytesIn = Table.AddColumn(AddedProtocol, "traffic.bytes_in", each [orig_bytes]),
AddedBytesOut = Table.AddColumn(AddedBytesIn, "traffic.bytes_out", each [resp_bytes])
in
AddedBytesOutNotice the inline comments, where the LLM flagged the traffic-byte direction as a Medium-confidence mapping that needs human review, and that self-flagging is among the most useful behaviors in the workflow because it tells the reviewer where to spend attention.
Step 4: semantic validation, the step that carries the workflow
Field names deceive, because Zeek's orig_bytes could plausibly map to OCSF's
traffic.bytes_in or traffic.bytes_out depending on whose perspective the
"in/out" describes. Without validation, you have roughly even odds of mapping the wrong direction,
which means every detection rule built on traffic volume triggers on inverted data, so the detection
looks like it's working when it's actually catching the opposite of what it claims to catch.
The validation method is dull and effective, because the trick is to compare the descriptions rather than the field names: build a side-by-side table of source-field description versus OCSF-field description, and check the alignment word by word.
Source field Source description OCSF field Alignment
orig_bytes Bytes FROM originator TO responder traffic.bytes_in MATCH (dst-perspective)
orig_bytes Bytes FROM originator TO responder traffic.bytes_out MISMATCH (wrong direction)
resp_bytes Bytes FROM responder TO originator traffic.bytes_out MATCH (dst-perspective)
proto Transport layer protocol connection_info MATCH (IANA mapping)Across the 12 projects, the validation pass caught roughly 80 percent of the LLM errors: directional flips, timestamp-format mismatches, protocol-number-versus-name confusion, null-versus-zero handling. I'm rounding aggressively here. The actual figure across the 12 projects was closer to 84 percent, but with N=12 the confidence interval easily includes anywhere from 70 to 90 percent. Call it "the majority of errors" and treat the exact number with appropriate skepticism.
What the validation pass does not catch is the remaining roughly 5 percent of errors that only surface once you run real queries against the OCSF data and compare results to the same query against the raw source, which is the production-testing step, and it cannot be skipped, since none of the LLM workflows I tracked shrank it.
Step 5: production deployment
Convert the LLM's Power Query M (or whatever intermediate form) into the actual production transformation language: Python in an AWS Lambda for near-real-time ingestion, dbt SQL for batch lakehouse processing, Spark for high-volume streaming. The LLM can help with the language conversion too; in practice this is straightforward mechanical translation once the semantic mapping is correct.
-- dbt model: zeek_conn_ocsf.sql
SELECT
4001 as class_uid,
4 as category_uid,
from_unixtime(ts) as time,
struct(id_orig_h as ip, id_orig_p as port) as src_endpoint,
struct(id_resp_h as ip, id_resp_p as port) as dst_endpoint,
struct(
CASE proto WHEN 'tcp' THEN 6 WHEN 'udp' THEN 17 WHEN 'icmp' THEN 1 END
as protocol_num
) as connection_info,
struct(orig_bytes as bytes_in, resp_bytes as bytes_out) as traffic
FROM {{ source('zeek', 'conn_log') }}Lambda versus dbt is a separate decision driven by latency tolerance and team skill mix. For OCSF-shaped detection on the hot path (near-real-time), Lambda is the more common pattern. For historical backfill and non-urgent sources, dbt is cheaper and easier to reason about.
The headline number, hedged
What "6–9× speedup" actually means with N=12.
Direct comparison from the 12 projects: manual mapping averaged roughly 2.5–3.5 hours per source across the tracked work, while LLM-assisted averaged roughly 15–25 minutes per source, which puts the ratio somewhere between 6× and 14× faster, with most observations clustering near 6–9×, and that clustering is what generates the "6–9× speedup" framing I've used elsewhere.
The honest version has three caveats. First, the range is wide because source complexity varies enormously. A well-documented CloudTrail mapping is genuinely 20× faster with LLM assistance, while a poorly documented custom-application log is more like 3× faster because the human prep work dominates. Second, the comparison is against my own manual baseline, which may not generalize; an engineer with deeper OCSF familiarity might map manually closer to 1.5 hours per source, which compresses the speedup to 4–6×. Third, the speedup is only realized if the domain-expert review actually happens. Skipping review collapses the accuracy to the 70–80 percent raw-LLM-output range, which fails compliance review and creates detection-rule bugs downstream. The "speedup" with review skipped is technical debt that materializes during the production testing step or, worse, after.
For an enterprise sketching a 50-source OCSF deployment plan: the manual-baseline estimate is 100–200 engineer-hours, realistically eight to twelve calendar weeks given other priorities. The LLM-assisted estimate (in my N=12 projects) comes closer to 12–20 engineer-hours, or two to four calendar weeks. That's the migration-cost shift that may change the OCSF adoption math, though the confidence interval on those numbers is wider than I'd want before betting a contract on them.
Where the LLM fails
The error patterns I saw across the 12 projects.
Five error patterns kept recurring. None are fatal (they're all caught in the validation step), but knowing what to look for makes the review pass faster.
- Byte directionality. The orig_bytes-versus-bytes_in problem described above. Most common error, roughly a third of all flagged issues. The LLM picks whichever direction sounds plausible from the field name alone.
- Protocol number versus name conflation. Zeek stores protocol as "tcp"; OCSF wants the IANA number 6. The LLM sometimes maps the string directly, which silently fails downstream numeric comparisons.
- Timestamp format mismatches. Unix epoch versus ISO 8601 versus millisecond-precision versus microsecond-precision. The LLM usually picks one and may not flag the edge cases (leap seconds, timezone offsets) that bite a year into production.
- Null versus zero semantics. Zeek may emit a missing field as either "-", null, or omitted entirely depending on the protocol; OCSF distinguishes null (unknown) from zero (measured, equals zero). The LLM frequently collapses both into one.
- Field reuse across multiple OCSF targets. The LLM sometimes maps a single source field to two OCSF fields without flagging the ambiguity (which one is canonical?). The validation pass needs to catch this explicitly.
One pattern I expected to see but did not: outright hallucinated OCSF fields that don't exist in the spec. Both GPT-4 and Claude Sonnet 3.5 stayed inside the OCSF vocabulary I gave them in the prompt. Anchoring the prompt to the specific OCSF class appears to be sufficient guardrail against hallucination at the field level. I'd revalidate that finding before assuming it holds for newer models; model behavior shifts in ways that may not be obvious.
My 95-percent figure deserves to sit next to what the broader text-to-structure literature reports, because OCSF mapping is a close cousin of the text-to-SQL problem and the published ceilings are sobering. The BIRD benchmark's roughly 81-to-82-percent execution-accuracy ceiling for automated systems against a 92.96-percent human baseline, and why even that overstates real reliability, is the outside view I work through in the AWS Security Lake teardown. The failure mode that worries me most is the one I flagged in Step 4 under a different name, the silent wrong answer, where LLM-composed SQL or mapping code executes cleanly, returns plausible output, and is semantically wrong, and validation cannot reliably catch it because the artifact under review looks correct. For OCSF mapping the consequence falls in the worst possible place. The common, well-documented sources are where the LLM is most accurate; the rare and adversary-relevant tail is where a plausible-but-wrong mapping is most likely and most expensive, because that's exactly the data a detection engineer is least equipped to eyeball for inversion.
The same failure shows up one step downstream, in querying the OCSF data rather than producing it, and there I now have a first-party measurement to set next to the BIRD ceiling. I ran a frontier model (claude-opus-class) as a default text-to-SQL path with full access to a synthetic OCSF corpus, roughly 177,000 events carrying one planted APT29-style intrusion chain, and asked it nine adversary-tail concept questions, eight independent trials each, scoring every answer correct, loud-wrong, or silent-wrong against a known gold (SDW Lab, June 2026, Tier B, directional pilot, n=9). On the simple lookups the model was correct and perfectly stable, eight of eight. On the aggregate, sequence, and identity questions, the ones a hunt actually turns on, it was silently wrong: a session count that should have read 35 came back 0, a distinct-asset count that should have read 2 came back 0, a dwell time of about 3,900 seconds came back near 1.2 million, and one query fabricated a cross-day kill-chain the data doesn't contain. The silent-error rate ran 0.49 across all nine questions and 0.84 on the adversary tail with nothing correct, and because the wrong answers held across all eight trials they read as stable, confident-wrong output rather than sampling noise. It is the same shape as the mapping caveat: right where the question is easy, wrong where it is adversary-relevant, and wrong in the particular way that returns a clean number instead of an error.
Two limits keep that from proving more than it does. Part of the scalar tail is structurally silent rather than a model failure, because a COUNT over an empty match returns a confident zero by construction; that is the analyst-facing pathology the bench exists to expose, but it is SQL behaving as designed rather than the model inventing a value. The run is also conditioned on a single default prompt with no ablation, so the honest claim is that a default text-to-SQL path is stably silent on the tail, not that no prompt could rescue it. And the bench does not endorse a fix, since handing the model an explicit graph structure did not beat a flat-facts control above the run-to-run noise, and retrieval rather than reasoning was the binding constraint, so what I can stand behind here is the problem, with the cure still open. The reason I keep pulling on it is where the failure sits, since the default probabilistic path is most confident and least reliable on exactly the adversary-relevant questions a detection program exists to answer.
What inspection misses
What catches the silent wrong answer.
Every method in this essay so far inspects the artifact, and the silent wrong answer is the one that survives inspection because the artifact looks correct. The reviewer reads the mapping and it reads plausibly, which is the whole problem, since a plausible mapping is exactly what a confident-but-wrong model produces, so the review pass and the model end up sharing a blind spot, where both are judging whether the mapping looks right and a directional flip or an actor mapped as an object looks right.
The check that doesn't share that blind spot is a deductive one. Give the mapping two independent groundings, the type of the OCSF path it targets and the semantic type of the source field itself, then write down which types are disjoint (an actor is not an object, a port is not a host), and a reasoner can derive that a mapping crossing those types is a contradiction. It derives that from the ontology rather than from whether the code reads plausibly, and no model sits in the loop, since it's an OWL reasoner (ELK via ROBOT, in my setup) over a hand-authored disjointness layer, so it returns the same verdict whether a frontier model, a small local model on air-gapped hardware, or a tired engineer at 2am wrote the mapping. That is the part the grounding-versus-rising-tide question I raise below doesn't touch, because a deductive check doesn't move with the model when the model isn't in it.
The limits are real and worth stating plainly. The disjointness layer is hand-authored, and I've adjudicated it over a small set of artifacts so far, so it catches actor-versus-object type-crossing and not yet the subtler lossiness, the enum collapsed to a coarser one or the structure quietly flattened, which is a different axis I won't claim it covers. Someone has to author the disjointness for each region of the schema, which is the ontological judgment that doesn't come for free. But inside its scope it does the one thing the review pass structurally cannot, which is to fail the build on a mapping that looks correct, and a check that only fires on mappings that look wrong is no help against an error whose whole nature is to look right.
So the deductive check sits naturally alongside the LLM workflow rather than replacing it. Let the model do the fifteen-minute generation, let the human review catch the roughly 80 percent of errors that are visible, and let the reasoner catch the type-crossing slice of the remainder that neither can see: generate fast, then prove what you generated against the schema's own logic. I work through that reasoner, and where it holds and where it breaks, in the OCSF-to-D3FEND grounding work.
The hybrid pattern
Most enterprises end up at roughly 70/25/5.
Across the 12 projects and the broader practitioner conversations I had at RSA Conference, re:Invent, and Black Hat between 2024 and 2025 (call it Tier C evidence: conference hallway data, not a structured survey), a consistent ratio kept showing up for OCSF deployment mix.
| Share | Approach | Sources | Why |
|---|---|---|---|
| Roughly 70 percent | Vendor automation | Standard log sources: AWS CloudTrail, VPC Flow, Office 365, Azure AD, standard EDR vendor exports, common SaaS audit feeds. | The vendor ships the OCSF mapping; the architect doesn't write transformation code. Fastest time-to-value. |
| Roughly 25 percent | LLM-assisted | Custom and legacy sources: application logs, custom security tools, proprietary vendor formats without native OCSF support, legacy SIEM normalization. | This is the bucket where the 15–25 minute per-source workflow earns its keep. |
| Roughly 5 percent | Manual | Compliance-critical or semantically unusual sources: financial transaction logs, healthcare audit trails, custom cryptographic protocols. | Anywhere the cost of a mapping error is severe enough that a human writing every line is justified. |
The ratio varies, since healthcare and finance organizations skew toward more manual work (closer to 10–15 percent manual) because of compliance posture, while tech-heavy organizations skew toward more vendor automation (closer to 80 percent) because their infrastructure is already AWS/Azure-native and the vendor mappings cover the common case.
The trend across the two-year window I tracked: the LLM-assisted bucket grew at the expense of the manual bucket. Organizations that previously did 90 percent manual and 10 percent vendor automation moved to roughly 60 percent vendor, 30 percent LLM, 10 percent manual as model capabilities improved. I'd expect the LLM share to keep growing into 2026 and 2027, but with N=12 and informal practitioner conversations as the basis, this is a directional observation, not a measured trajectory.
Adjacent question
Where does AWS Security Lake fit?
AWS Security Lake is the closest thing to a managed OCSF service in market today. It normalizes a defined set of AWS-native sources (CloudTrail, VPC Flow, Route 53, EKS audit logs) into OCSF on ingest, lands the result as Parquet in an S3 bucket, and registers the tables with AWS Glue for downstream querying. For the standard-source bucket (the 70 percent of the OCSF deployment that doesn't need custom mapping) Security Lake is doing the LLM's job and the manual mapper's job for you, with no engineering time required.
The deeper question is what Security Lake doesn't cover. Third-party SaaS audit logs (Okta, GitHub, Microsoft 365 outside Azure-native ingestion), on-premises sources (Zeek, firewall syslog, EDR vendor feeds that don't land in S3 natively), and any custom application telemetry all fall outside the Security Lake automation envelope. That's the bucket where LLM-assisted mapping earns its keep, and also where the "Security Lake gives me OCSF for free" narrative breaks down for enterprises with significant on-premises or multi-vendor SaaS footprints.
I wrote about the broader Security Lake architecture, including the OCSF mapping coverage gaps, in the AWS Security Lake teardown. The short version is that Security Lake is a strong product for the AWS-native slice of OCSF adoption, and the LLM-assisted workflow is what fills the gap for everything else.
Schema architecture context
Schema-on-read versus schema-on-write changes the urgency.
The OCSF translation tax is felt differently depending on whether your downstream architecture is schema-on-write (Iceberg lakehouse, Parquet files, structured tables) or schema-on-read (Splunk, Elastic, anything that parses fields at query time from a flexible source format).
Schema-on-write architectures pay the OCSF translation cost once, at ingest, so every query downstream gets OCSF-shaped data for free, and the migration cost is concentrated in the one-time mapping work, which is exactly the work LLMs may shrink. Schema-on-read architectures pay the cost at every query instead, because every detection rule has to translate from source-shape to OCSF-shape on the fly and every analyst writing ad-hoc queries has to know both the source and OCSF schemas, so the cost is amortized across many small queries instead of one big migration.
For schema-on-write deployments, which is where the lakehouse argument leads, the LLM-assisted mapping workflow is the migration accelerator. For schema-on-read deployments, the LLM may help with the per-query translation logic, but the structural cost stays distributed. I wrote about the broader architectural trade-off in schema-on-read versus schema-on-write. The short version: if you're going to land on OCSF anyway, doing it once at ingest is cheaper than doing it every time at query time, and the LLM is what makes the once-at-ingest path feasible at fifty-source scale.
Honest gaps
What I haven't validated, and what may break the claim.
Five things I'd want to test before treating any of the numbers in this essay as reliable enough for a production deployment decision:
- Sample size beyond N=12. A structured study with 50–100 mapping projects across diverse organizations would tighten the confidence intervals on speedup and accuracy considerably. The current N=12 is enough to motivate the directional claim, not enough to defend specific numbers under scrutiny.
- Newer-model revalidation. The 70–80 percent raw-output accuracy and the 95 percent post-review accuracy were measured against GPT-4 and Claude Sonnet 3.5. Claude Sonnet 4.5, GPT-5, and equivalent 2026-era models likely perform differently (possibly better, possibly with different error patterns). Version-pinning matters, and I haven't re-run the methodology.
- Exotic source coverage. The 12 projects skewed toward well-documented sources (Zeek, AWS, Okta, common SaaS). Custom application logs and proprietary vendor formats were underrepresented. The accuracy claim may degrade meaningfully on those harder cases.
- Long-term drift. Source schemas change. OCSF schemas change. A mapping that's 95 percent accurate today may degrade as either side evolves. I haven't tracked re-mapping cost over multi-year deployments, which is the real lifecycle cost.
- Failure-mode auditing. The 5 percent of errors that survive the review pass and only surface in production query comparison: what do those look like, how do they correlate with detection-rule false negatives, and how much downstream debugging do they cause? I have anecdotes, not measurements.
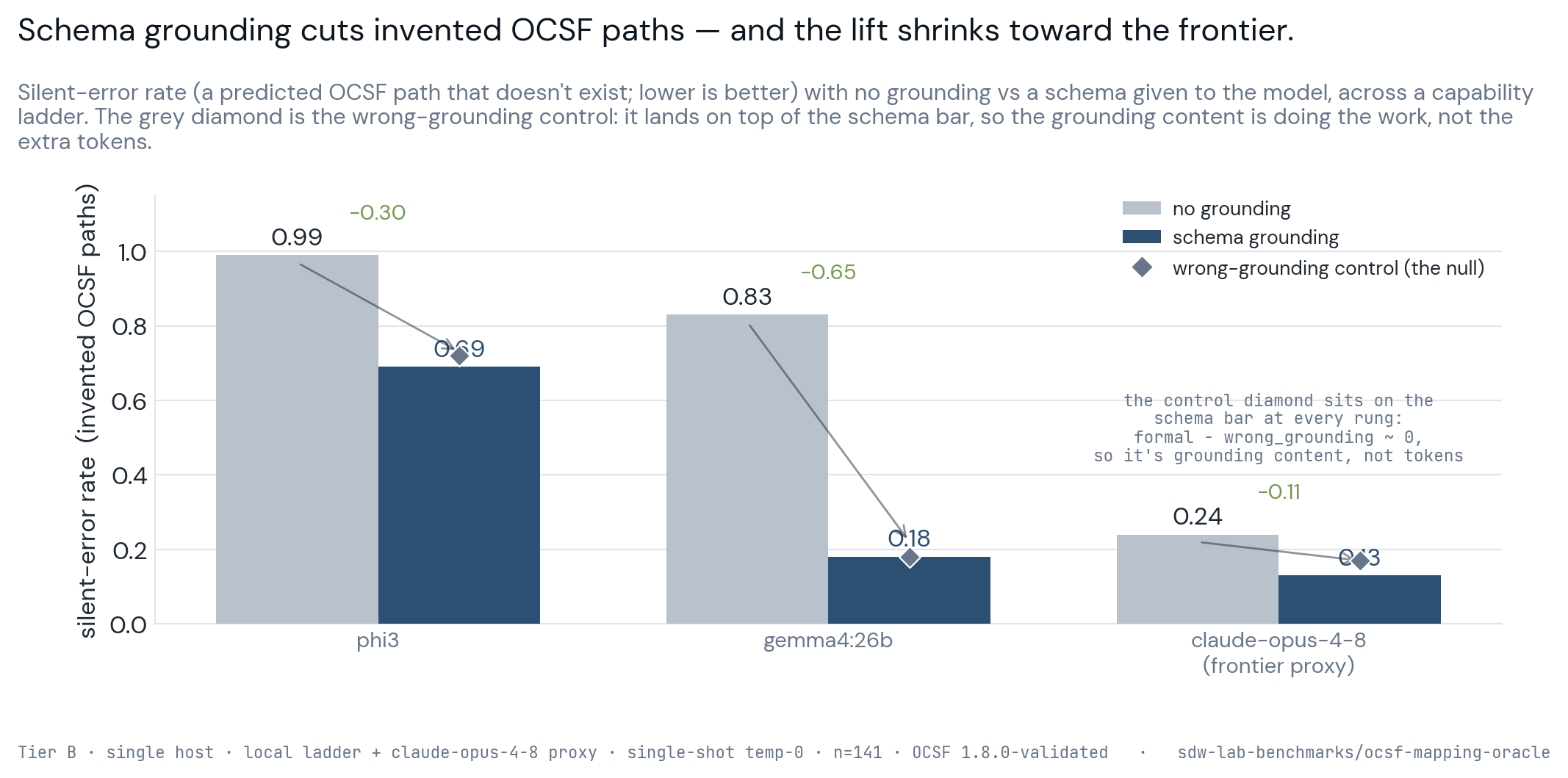
- Grounding versus the rising tide. I've pinned the jump from 70–80 percent raw output to 95 percent partly on the explicit OCSF-class anchoring in the prompt (Step 2). That attribution is the part of this essay I'm least sure of. Is the lift coming from the grounding architecture, the act of constraining the model to a named class and a curated field subset, or is it coming from base-model maturity, the general capability tide that lifts every prompt regardless of how I scaffold it? Those two explanations have very different implications. If the grounding is doing the work, the methodology is defensible and portable across models. If the base model is doing the work, the anchoring is decoration and the real driver is whichever frontier model I happen to be holding. The clean test is a fixed model run with and without the class-grounding anchor, holding everything else constant, and I've now run a first cut of it (SDW Lab, June 2026, Tier B). The result splits "grounding" into two things the prompt had been bundling together. A correct conceptual note about what the OCSF class means does not beat a deliberately wrong one (the difference between the two was −0.021, inside the noise) at the frontier, on 705 prompts against claude-opus-4-8. What actually cuts invented OCSF paths is the schema constraint, handing the model the valid-path list and rejecting anything off it (−0.113 against no constraint). So the lever is the harness, the schema-validity enforcement, not the ontological prose, and that holds across the capability range rather than only at the top: running the same mapping oracle against a weak local model (phi3 3.8B) had it inventing a non-existent OCSF path roughly 69 percent of the time and returning plausible-wrong-but-no-error SQL about 9 percent of the time, while a stronger model (gemma 27B) dropped to 18 percent invented-path and 0 percent silent, failing loud on the hard queries instead. The stronger model is safer because its failures are visible, not because it is always right, which lines up with Microsoft's NL2KQL report of roughly 58 percent accuracy at around 99 percent surface validity. That reframes the gap I'd left open: the grounding prose I leaned on in Step 2 looks closer to decoration, and the part of the scaffold that earns its place is the schema check, which is also the part I can run on air-gapped hardware without a frontier model in the loop.
None of these break the directional claim that LLM-assisted OCSF mapping appears materially faster than manual mapping at comparable accuracy. They're reasons to size expectations correctly, and to treat any vendor or consultant quoting precise speedup numbers off this kind of work with the same skepticism I'm applying to my own.
Why this matters
The OCSF migration tax is the adoption blocker.
OCSF as a standard has the easier political question mostly settled, because AWS pushes it via Security Lake, Splunk supports it via an app, the OCSF community ships quarterly schema updates, and the contributor list keeps growing, so the "will OCSF win" question is increasingly a "when does the long tail catch up" question, not an "if" question.
The harder operational question is what it costs an enterprise to actually get its sources into OCSF shape, and that cost is what determines whether OCSF stays a standard people talk about or becomes a standard people deploy. At two to four hours of skilled-engineer time per source, the 50-source enterprise pays 100–200 hours of migration work before any OCSF-shaped detection runs, and that cost stalls deployments, which is the reason most enterprises in 2024 and 2025 talked about OCSF while still running on their existing vendor-shaped schemas.
If LLM-assisted mapping cuts that cost from 100–200 hours to 12–20 hours, and my N=12 evidence says it may with all the small-sample caveats, the migration math changes, though not by enough to make OCSF adoption automatic, only by enough to move the cost from "blocks the project" to "fits in a quarter," and that shift is what may turn the OCSF adoption curve from slow to steep.
The honest framing is that OCSF is one of four foundational standards in the security lakehouse stack, and the schema layer carries weight the rest of the stack depends on, so the translation tax determines whether that layer gets adopted at all, which is the tax LLMs may shrink meaningfully. The evidence behind that claim is thinner than I'd like (N=12, my own time-tracking, model versions that are already a year old), and the directional argument is real enough to act on, so treat the numbers as starting hypotheses to validate against your own workload, not as benchmarks to quote back at vendors.