
Technology deep-dive
MLOps tools for threat hunters.
A mature threat hunt is a small data-science experiment in disguise. The hunter forms a hypothesis, queries logs, measures precision and recall, documents what worked, and shares it with the team. That is the scientific method applied to security telemetry. The tooling the rest of the data world uses for this work (notebooks, experiment trackers, data versioning, quality tests, feature stores) has names that sound foreign to most SOC analysts, even though the work underneath the names is work those analysts already do.
Reading time: about 18 minutes. Evidence tier: B overall (SANS Hunting Maturity Model framework, Splunk PEAK framework, vendor documentation for MLflow, Kubeflow, Feast, ClearML, and Weights & Biases). The HMM-to-tool mapping is my synthesis, not a published framework, flagged as such where it matters. I have not independently benchmarked any of these tools on production OCSF data.
The reframing
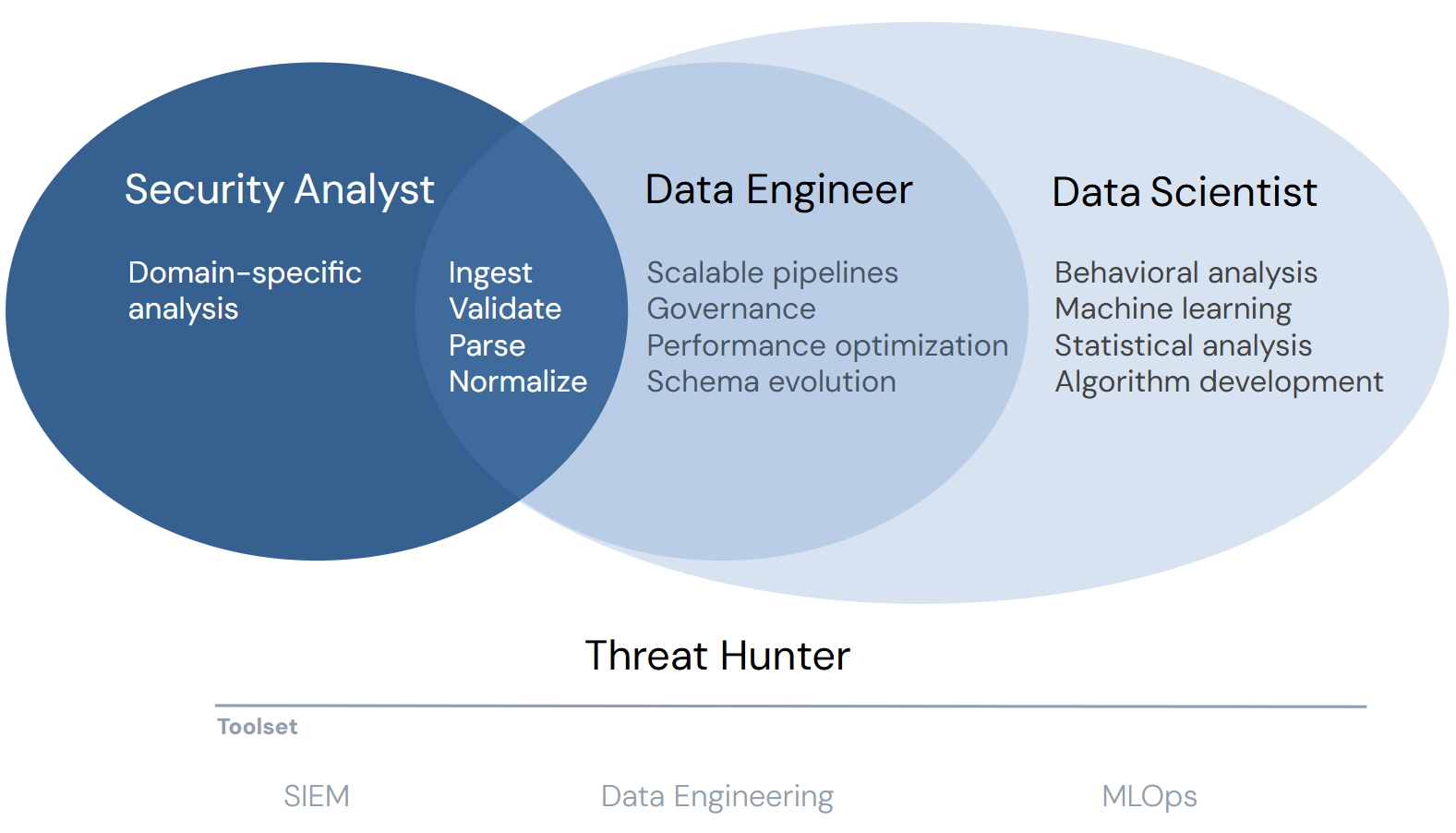
Threat hunting is data science with a different vocabulary.
A typical Tuesday for a hunter at the HMM2-to-HMM3 transition looks like this. You open the SIEM and form a hypothesis, say that "adversaries are using compromised cloud credentials to disable CloudTrail logging," and then you write a query that scans for API calls modifying logging configuration and filter out the noise, so that forty-seven raw results walk down to twelve true positives. You write the finding up, share it with the team, and maybe codify the best variant as a detection rule.
Every step of that workflow has a data-science name, because the hypothesis is a hypothesis, the query is exploratory data analysis, the forty-seven-to-twelve precision number is model validation, the write-up is reproducible research, and the detection rule is a deployed model. The reason most hunters don't call it that is partly cultural ("data scientist" reads as a different role with different credentials) and partly because the tools the data-science world uses for this work haven't been packaged for SOC teams.
The Splunk PEAK framework (Prepare, Execute, Act, Knowledge) and the SANS Hunting Maturity Model both describe this same workflow shape. PEAK is the per-hunt cycle. HMM is the organizational maturity ladder: HMM0 (no hunting) through HMM4 (leading with automation). I cover the PEAK mechanics in PEAK plus lakehouse hunting, and the HMM-to-detection-engineering progression in detection maturity. This piece is about the tools that sit underneath both.
One thing I want to set up front: none of what follows requires a PhD, a neural network, or years of Python. If you can write a SQL query and read a Markdown document, you have the prerequisites. The tools amplify the hunting skills you already have. They don't replace them, and they don't turn a hunt into a research paper unless you want it to.
I came to this reframing the slow way, by being the person hunters came to. For years, threat hunters kept landing at my desk for query help. They could hunt; what they couldn't always do was the data part, the work of expressing the question against the logs they had, making it run across the depth and duration the hunt actually needed, and shaping the results into something they could reason over. The good ones had taught themselves that craft because the job demanded it, and what they were doing underneath was querying at scale, building features, and hunting for patterns across breadth and time, which is data science whether or not anyone in the room would have used the words. That is the reframing from the inside, and it cuts two ways. Hire actual data scientists into hunting, and give the hunters you already have data-science-grade instruments instead of leaving them to improvise against a SIEM search bar.
The five categories
What MLOps tooling is, in hunter terms.
MLOps (machine learning operations) is the discipline of running data-science workflows as production systems rather than one-off experiments. The category was built for teams shipping ML models, but the underlying tools solve four problems that any mature hunter recognizes: reproducibility, collaboration, versioning, and quality validation.
Five tool categories cover most of what a HMM2-to-HMM4 program needs:
- Interactive notebooks. Jupyter and JupyterLab. The work surface where the hunt lives.
- Experiment tracking. MLflow, ClearML, Weights & Biases. The system of record for which hunt variant beat which.
- Data versioning. DVC (Data Version Control). The way you reproduce a hunt result six months later against the same data.
- Data quality testing. Great Expectations. The early-warning system for schema drift in the log sources you depend on.
- Feature stores. Feast. Centralized, reusable computations across detection models. An HMM4 concern, not an HMM2 one.
A sixth category, orchestration platforms like Kubeflow, sits adjacent to all of these. Kubeflow runs ML pipelines on Kubernetes; it's the production-deployment piece, not the hunt-development piece. I mention it because security teams already running Kubernetes platforms sometimes ask about it. For HMM2-to-HMM3 work, it's overkill. For HMM4 production detection pipelines, it earns its keep, though the operational complexity is real.
Notebooks
Jupyter as the hunt surface.
A Jupyter notebook is a document that mixes code cells (SQL, Python, shell), Markdown narrative, and visualizations in one file. You run the cells top to bottom and the document carries the working state: query, dataframe, chart, paragraph explaining what you saw. Save the file, commit it to Git, and the hunt becomes a reproducible artifact rather than a transient SIEM session.
The contrast with a SIEM console is most of the argument, because a SIEM search lives in browser state, so when you close the tab the query, the timeline filter, and the visualization choices are gone. The hunter who comes back six months later to revalidate the finding writes the same query from scratch (sometimes against schema that has drifted in the meantime) and may or may not reach the same conclusion. A Jupyter notebook checked into Git has the query, the filter, the chart code, and the narrative pinned together. Re-running it tells you whether the result still holds.
What that looks like in practice for a cloud-control-plane hunt:
- Cell 1: SQL query against the CloudTrail Iceberg table, returning a pandas dataframe.
- Cell 2: Python filter that strips out known service-role principals and keeps user identities.
- Cell 3: Matplotlib chart of API-call frequency over the investigation window.
- Cell 4: Markdown paragraph describing the hypothesis, the data, and the false-positive pattern that survived filtering.
- Cell 5: The candidate detection rule, written out as SQL, ready to lift into the SIEM or detection-as-code repo.
Time to first productive notebook is in the 2-to-8-hour range for an analyst who already writes SQL and reads Python comfortably. That estimate is drawn from training-workshop reports rather than a controlled study, so treat it as directional. Analysts who haven't worked with the pandas DataFrame model (the table-like object that holds query results in memory) tend to land at the upper end of that range; the shift from "SIEM result grid" to "DataFrame you can slice programmatically" is the one conceptual hurdle.
Jupyter is free, open source, and runs on a laptop or a shared server. JupyterHub adds multi-tenant hosting for a team. The integration surface is wide: DuckDB for local Iceberg queries, SQLAlchemy for ClickHouse or StarRocks, REST calls for catalogs, and embed cells for Grafana. For most HMM2-to-HMM3 teams, Jupyter is the only tool on this list they should adopt in the first six months.
Experiment tracking
MLflow, ClearML, and Weights & Biases.
Experiment tracking is the system of record for "I tried ten variants of this detection rule. Which one wins on precision and recall, and what exactly was variant seven?" Spreadsheets are the default tool, and they work for two or three variants but break by variant ten, because no one remembers to update the spreadsheet consistently and the artifacts (the query text, the chart, the dataset snapshot) live somewhere else.
An experiment tracker records three things per run: parameters (what you fed the experiment: dataset, timeframe, threshold, query text), metrics (what came out: precision, recall, true-positive count, false-positive count), and artifacts (the files: the detection rule, the notebook, the chart, the report). The UI lets you compare runs side by side and click through to the exact configuration that produced any given result.
The three credible options in early 2026:
- MLflow. Open source, originally from Databricks. The most widely adopted option. Self-hostable on a small VM with a PostgreSQL backend and S3-compatible artifact storage. The UI is functional rather than polished. This is what I would default to for a security team standing up experiment tracking for the first time, and what most public documentation in the security-data-science space assumes.
- ClearML. Open source, with a hosted SaaS tier. Stronger out-of-the-box experience than MLflow, including a more polished UI and built-in pipeline orchestration. Smaller community, which matters if you're going to lean on Stack Overflow and blog posts to unblock yourself.
- Weights & Biases. Commercial SaaS, with a generous free tier for individual use and paid plans for teams. The UI is the best of the three by a useful margin, and the collaboration features (commenting on runs, sharing reports) are designed for team workflows. The trade-off is that you're sending experiment metadata to a vendor cloud, which matters more in security than in most domains.
For a hunter, the unit of "experiment" is a hunt campaign or a detection-rule variant. The parameters are the dataset window, the threshold values, and the query text. The metrics are precision, recall, alert volume, mean-time-to-investigate. The artifacts are the notebook, the SQL file, and any charts worth keeping. The work to instrument this is a few extra lines per notebook: start a run, log parameters, log metrics, log artifacts, end the run.
The honest caveat: experiment tracking pays off when you have ten or more variants to compare. Below that, a Markdown table in the notebook is sufficient, so I would not adopt MLflow on day one but rather after the first ten-to-twenty Jupyter hunts, when the cost of forgetting which variant you ran starts to bite.
Data versioning
DVC and the "same data six months later" problem.
DVC is the simplest tool on this list to explain and the hardest to convince a team they need.
The pitch: it is Git for data. You version multi-terabyte datasets using small metadata files
in Git, with the actual data living in object storage (S3, Azure Blob, GCS). A
dvc checkout against a tag pulls the exact bytes present when that tag
was created, which gives you time travel without copying petabytes around.
Why a hunter cares: detection-rule validation is fragile. You tune a rule against ninety days of CloudTrail data, measure 86% precision, and ship it. Three months later, you tune it again and want to know whether the change moved precision from 86% to 92% or whether it stayed flat and the apparent gain came from log volume drift. Without a frozen baseline dataset, you can't tell. With DVC, you check out the same ninety-day window you used originally and re-run the validation against bit-identical data.
The Iceberg-specific wrinkle: Iceberg already has snapshot IDs and time-travel queries. For teams already on Iceberg, the DVC layer mostly captures the snapshot ID as metadata rather than copying the data. Iceberg vs Delta Lake covers the table-format mechanics. The honest position is that for an Iceberg-native shop, DVC may be redundant; Iceberg snapshots plus a tagging convention can do the job. DVC earns its keep when you're moving filtered subsets out of Iceberg into training datasets for ML-based detection, or when you need to track non-Iceberg artifacts (a CSV of known-malicious IPs, a parquet file of labeled training data) with the same workflow as the code.
Learning curve is four-to-six hours for someone who already understands Git. The harder part is operational: provisioning the remote storage, agreeing on a tagging convention, and getting the team to actually create tags before running validation experiments. That last item is the one that determines whether DVC pays off or sits unused.
Data quality
Great Expectations and the silent-detection-failure problem.
Great Expectations is a Python framework for writing data-quality tests ("expectations") that run automatically against your tables and alert when they fail. An expectation is a declarative assertion: this column must exist, this column must not be null more than 5% of the time, this column's values must fall in this range, this table must have rows from the last hour.
For a hunter, the failure mode this addresses is the silent miss. Your detection rule queries a
CloudTrail field called userIdentity.principalId. AWS renames the field, or your
pipeline normalizes it differently after an OCSF mapping update, or the source schema rolls
over. The query keeps running and returns zero results, and zero results looks identical to "no
adversary activity," so the adversary operates undetected for as long as it takes someone to
notice the change.
An expectation suite for CloudTrail might assert:
- Required columns are present, including the OCSF-normalized identity fields.
- The
event_timecolumn has rows within the last 60 minutes. - The
regioncolumn's distinct values stay inside the expected set. - The
eventNamecolumn's null rate stays under 1%.
Great Expectations runs the suite on a schedule. When something fails, the failure routes to Slack or PagerDuty before the detection rule misses anything. The framework also generates a data-quality report you can hand to the source owner ("your CloudTrail feed broke at 03:14, and here's the specific assertion that caught it") which tends to shorten the time-to-fix.
The cost is real: writing expectations is its own skill, and a bad expectation suite generates alert noise no more useful than a noisy SIEM. The Great Expectations CLI has a profiler that generates a starting suite from a sample of your data, which is a reasonable way to start, and from there you prune the assertions that don't matter for your actual hunts. Six-to-ten hours to a working first suite is typical.
Feature stores
Feast — only after you have multiple ML detectors.
A feature store is a system that computes derived attributes ("features") from raw data once, stores them, and serves them consistently to every model that needs them. Feast is the open-source reference implementation. The problem it solves: when ten different detection models all need "number of failed logins per user in the last 24 hours," computing that feature ten times against the raw logs is wasteful, and getting ten slightly different implementations is worse than wasteful. It's the kind of silent inconsistency that produces contradictory model outputs.
Feast lets you define the feature once, point it at the raw OCSF-normalized log tables, and have every model pull from the same materialized result. There's an online store for low-latency serving (typically Redis or DynamoDB) and an offline store for training and batch scoring (typically Parquet on object storage). The training-serving consistency guarantee, that the model sees the same feature shape at training time and at scoring time, is the structural advantage over ad-hoc feature pipelines.
The reason this is an HMM4 concern, not an HMM2 one: feature stores are infrastructure for ML-based detection. If you have one ML model, you don't need a feature store; you have a pipeline. If you have ten, you need a feature store because the alternative is a maintenance nightmare. Most security teams I talk to are at zero-to-two ML models in production. For those teams, Feast is premature and the operational burden (the online store, the offline store, the materialization jobs, the registry) is not paid back.
I include Feast because it shows up in MLOps reading lists and the question "do we need a feature store" lands on architects' desks. The honest answer for most security teams in 2026 is "not yet, and you'll know when you do."
HMM mapping
Which tools, which maturity level.
The SANS Hunting Maturity Model defines five levels. HMM0 is no hunting. HMM1 is alert-driven triage. HMM2 is procedural hunting (applying community playbooks from MITRE ATT&CK and threat reports). HMM3 is innovative hunting (developing novel hunts, applying data-analysis methods, measuring effectiveness). HMM4 is leading with automation: codifying mature hunts into ML-assisted production detection.
The mapping below is my synthesis of where each tool earns its keep against the HMM ladder. It is not a published framework. Treat it as a working hypothesis to test against your own program. The general shape (start light, add tools as the cost of not having them shows up) seems to hold across the teams I've worked with.
HMM2 to HMM3 transition
Goal: turn procedural hunts into a library of documented, reproducible, peer-reviewed playbooks. Add Jupyter first, and document one hunt end-to-end in a notebook, commit it to Git, have a teammate review it, and repeat ten times, because that single workflow change is the highest-leverage move on the list.
Great Expectations follows in the same phase. After your second or third hunt fails because a log source schema changed without anyone noticing, the data-quality framework starts paying for itself.
What to defer at this stage: MLflow, DVC, Feast. You don't have enough variants yet to need experiment tracking, you're not validating against frozen datasets yet, and you have no ML models. Adopting these too early creates infrastructure overhead without proportional benefit.
Timeline I'd plan against: six-to-twelve months at this phase. Success looks like 20-or-more documented hunts in Jupyter, five-or-more reproducible playbooks with precision over 80%, data quality tests on the critical log sources, peer-review as part of the hunt workflow.
HMM3 innovative hunting
Goal: build a library of validated hunts and start identifying automation candidates. Add MLflow (or ClearML, or Weights & Biases; pick one and commit) once you're routinely comparing ten-plus variants of a detection rule. The experiment tracker becomes the system of record for which variant ships.
Add DVC when you start validating detection rules against frozen historical windows. If you're Iceberg-native, the lighter version of this is a tagging convention against Iceberg snapshot IDs and a notebook that pins the snapshot it ran against. Either approach works; the discipline matters more than the tool.
Continue Jupyter and Great Expectations from the previous phase, and keep deferring Feast and Kubeflow.
Timeline: 12-to-18 months. Success looks like 50-or-more hunt campaigns tracked in the experiment tracker, 10-or-more versioned baseline datasets, and five-or-more validated detection rules ready for automation with precision over 90%. The five rules at over 90% precision are the input to the HMM4 transition.
HMM4 leading with automation
Goal: automate the routine investigation work that the validated playbooks now describe. The realistic ceiling for HMM4 automation in a human-in-the-loop SOC is roughly 30-to-40% of routine investigations. I work through why it sits there, and why agent-native claims in the high nineties don't yet hold up, in the agentic-SOC reality piece.
At this phase, the full toolchain comes into play, with Jupyter for prototyping new techniques, MLflow (or equivalent) for tracking model versions in production, DVC for training datasets, Great Expectations for production data-quality gates, Feast for the feature layer once you have multiple ML detectors, and Kubeflow (or an equivalent orchestrator: Airflow, Prefect, Dagster) for running the production detection pipelines on Kubernetes.
What distinguishes HMM4 from earlier phases is the workflow move from "human runs the hunt, tool documents it" to "tool runs the playbook, human reviews exceptions." The toolchain is the same; the operating model changes. That shift takes 12-to-24 months from the start of HMM3 maturity, and the limits on it are organizational (analyst workflows, on-call structure, escalation paths) more than technical.
I want to flag one debate that lives at this maturity level. Some agent-architecture vendors claim higher automation rates (98% or more) via investigation-coordinator agents that orchestrate end-to-end. That model exists as a research direction and as a small number of production deployments. I don't have independent evidence that it generalizes, and the published 30-to-40% MLOps automation number from Expel is the floor I trust. Treat the higher agent-architecture claims as Tier C-to-D until production validation lands.
Lakehouse integration
How the toolchain connects to the data platform.
The MLOps tools assume a data platform underneath them. For a security team running an Iceberg lakehouse with a query engine (StarRocks, ClickHouse, Trino, or DuckDB) and a catalog (Polaris, Unity, Glue), the integration points are straightforward:
- Jupyter to Iceberg. DuckDB's
iceberg_scan()reads Iceberg tables directly from notebooks. PySpark or Trino's Python client work for larger windows. SQLAlchemy connectors give SQL access to ClickHouse and StarRocks for engines that don't speak Iceberg natively. The Arrow plus ADBC path is the columnar-native version of this, and removes the row-to-column serialization tax on result sets. - MLflow artifact storage. Point MLflow at the same object storage that backs your Iceberg tables. The PostgreSQL backend for the tracking database can co-locate with your catalog's database to reduce operational surface.
- DVC remote storage. Same object storage, different prefix. When you need to version an Iceberg-derived training dataset, the DVC metadata file captures the Iceberg snapshot ID alongside the file hash so the lineage is recoverable.
- Great Expectations against OCSF tables. The framework's SQL connector runs assertions against any engine that speaks SQL. The most valuable assertions are at the OCSF-normalized layer: required fields present, expected categories present, time windows current. Schema-drift detection at this layer catches a useful share of the silent-detection-failure problem.
- Feast against Iceberg. Feast can use Parquet on object storage as the offline store and a separate online store (Redis, DynamoDB) for serving. The feature definitions point at OCSF-normalized tables, which means the feature layer composes with the schema standard rather than fighting it.
The composability that matters: Iceberg as the table format, OCSF as the schema, Arrow as the in-memory format, and a query engine of your choice, none of which require you to commit to a particular MLOps tool. You can swap MLflow for ClearML without re-architecting the data layer. That's the same argument I make for Iceberg over Delta in the table-format piece, applied one layer up.
Honest limits
What this approach does not solve.
Six honest limits, none of which I'd hide from a stakeholder evaluating this stack:
- Tooling does not produce hunters. Jupyter does not generate hypotheses, and MLflow does not invent novel detection techniques, because the tools amplify the analytical discipline of a team that already has it, so a team that hasn't formed hunting hypotheses before will not start because they installed JupyterLab.
- The HMM-to-tool mapping is my synthesis. SANS publishes the maturity model; the tool placements against the maturity ladder are an opinion that fits the teams I've worked with. Other practitioners will draw the lines differently and may be right for their context. Treat it as a starting point, not a prescription.
- I have not independently benchmarked these tools on production OCSF data. The descriptions of where each tool earns its keep are drawn from documentation, training workshops, and conversations with practitioners, not from a controlled study. A security-specific benchmark of MLflow tracking overhead against high-volume hunt campaigns is on the lab roadmap and would be Tier B evidence at best when it lands.
- The 30-to-40% HMM4 automation ceiling is Tier B, not Tier A. Expel's published number is a single vendor's reported outcome on a particular managed-detection workload. The structural argument for why it sits at roughly that ceiling (human-centric SOC workflow, MLOps tools designed for human-in-the-loop) is plausible. The number may shift as agent architectures mature.
- The operational cost is real. Running MLflow, DVC, Great Expectations, and Feast as production infrastructure is non-trivial. For an HMM2 team starting here, the message is: do not adopt all five at once. The benefits compound, but so does the maintenance burden. The "start with Jupyter, add the next tool when the cost of not having it bites" sequencing is deliberate.
- The toolchain is itself an attack surface. Every tool here is a service that holds your detection logic, your dataset pointers, and often the credentials a run needs, which makes the MLOps layer a target in its own right rather than neutral plumbing. MLflow's tracking server has a documented record of unauthenticated path-traversal and remote-code-execution flaws, and model artifacts serialized as pickle, joblib, or torch weights run arbitrary code on load, so a poisoned model file is an entry point and not just bad data. The discipline that answers this has a name, SecMLOps: keep these services off the public internet, rotate default credentials, constrain artifact paths, and prefer pickle-free formats like ONNX or Safetensors. I work through the CVEs and the hardening checklist in the Jupyter-to-MLflow piece; the point to carry here is that standing up data-science tooling expands the surface you have to defend, and a service that stores your security logic earns the same patching and network hygiene as anything else in production.
None of these are reasons to dismiss the approach, but they are reasons to size expectations and sequence adoption correctly.
Practical guidance
What to do in 2026.
Four moves I'd actually recommend, ordered by how cheap they are to execute:
- Adopt Jupyter for one hunt this week. Pick a hunt campaign you already know the answer to. Document it in a notebook end-to-end: query, filter, chart, narrative. Commit it to a Git repo. Have a teammate review it. That single exercise produces the template for every subsequent hunt and exposes the rough edges (data access, library installs, kernel choice) on a low-stakes problem rather than a live investigation.
- Treat Great Expectations as the second adoption, not the fifth. Pick the three log sources your detection rules depend on most. Write a minimal expectation suite for each: required fields present, freshness within the expected window, distinct values inside the expected set. Route failures to the channel your team actually monitors. The cost of building this is hours; the cost of a silent detection failure can run into weeks of adversary dwell time.
- Defer experiment tracking, data versioning, and feature stores until they earn their keep. The trap with MLOps tooling is adopting it all at once because the ecosystem is well marketed. The marketing is mostly for ML platform teams shipping models, not for hunters documenting hypothesis-driven work. Adopt MLflow when you have ten variants to compare and a spreadsheet that has fallen out of date. Adopt DVC when you need to revalidate against bit-identical data. Adopt Feast when you have multiple ML models reading the same features. Not before.
- Measure precision and recall on the hunts you ship. This is independent of any tool on this list, because a hunt that ships a detection rule without a precision number tends to produce alert noise, while a hunt that ships with measured precision and recall against a labeled or red-team-validated dataset has the property that makes it promotable to automation later. The MLOps tooling exists to make this discipline easier, so it is worth adopting, but it does not substitute for measuring in the first place.
The reframing I started with is the one I want to land on, which is that a mature threat hunter is doing data-science work whether they call it that or not, so the MLOps tools are for the role you already play, with better instruments, rather than for some different role you'd have to become. Start with the instrument that costs the least and pays back the fastest (Jupyter for hunt documentation) and let the rest of the toolchain earn its place as the discipline matures.