
The measurement
Context collapse, measured on real attack data.
When you collapse security telemetry into a single coarse store to save money, the detection recall you lose isn't spread evenly, and it falls hardest on the queries that catch a competent intruder. I argued that in the abstract, then built a lab test that supported it, then got suspicious of my own test and rebuilt it with nothing I controlled in the loop. The gap survived, and it got smaller. That second part is the honest part.
Reading time: about 9 minutes. Evidence tier: B for the mechanism, reproducible, first-party, on real public attack data with third-party rules, single machine, one dataset. The in-the-wild magnitude stays Tier C until an independent practitioner confirms the coarse store resembles what shops actually build. This is the companion measurement to the flattening essay, which covers the mechanism; here I am only trying to put an honest number on it.
The claim, and the problem with proving it yourself
A gap I had every incentive to find.
The data-modeling world calls it context collapse: the distinctions among who did what, when, where, and what it meant, erased to save space or time. In security the economics push hard toward that collapse, and hardest on the high-volume sources where an intruder hides, so a coarse normalized store is the rational response to a dollar-per-gigabyte SIEM bill. My claim was narrower than "coarse stores are bad." It was that the loss is disproportionate: routine reporting queries tolerate coarse grain, while adversary-relevant queries, the ones that need an exact command line or an inter-arrival timing or a rare DNS name, are exactly the ones coarsening breaks.
The first time I measured it, I built the corpus, wrote the queries, planted the needle, and chose which queries counted as adversary-relevant. The result was a large gap, and I didn't trust it, because a benchmark where I control the rules, the attack, the split, and the target is a benchmark I can talk into any answer I want. The commercially convenient outcome and the measured outcome agreed, which is precisely when a measurement deserves the most suspicion.
The de-gamed test
Take my hands off every lever.
So I rebuilt the test to remove the four things I had controlled. The rules are cloned verbatim from
SigmaHQ, the community detection corpus, compiled through pySigma to SQL with nothing changed but the
table name, so I am not writing detections that flatter my point. The data is the MITRE ATT&CK APT29
evaluation telemetry, a real published adversary emulation, not a corpus I generated. The split between
adversary-relevant and routine is each rule's own attack. technique tags checked against
MITRE's published list of APT29 techniques, so the rules and MITRE decide which bucket a rule lands in,
not me. And the coarse store applies a documented, volume-driven normalization default, blind to the
rules. The faithful store keeps the fidelity. Of 2,853 rules scanned, 2,277 routed to a supported log
source, 2,276 compiled, and 54 actually fired on the faithful store; those 54 are the population, the
rules with something real to lose.
The metric is deliberately plain: for each rule that fires on the faithful store, recall loss is one minus the ratio of its matches on the coarse store to its matches on the faithful one. If the disproportionality is real, it should show up as adversary-tagged rules losing more recall than the rest, with no needle I defined anywhere in the loop.
The result
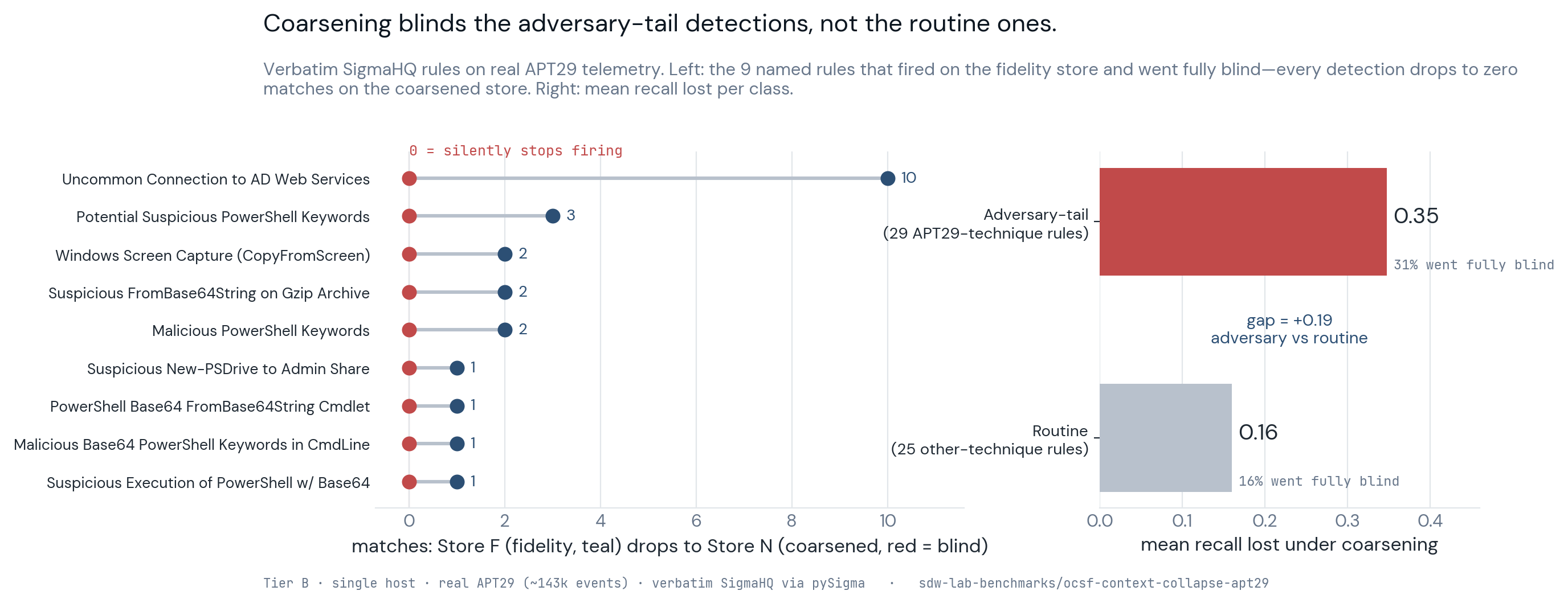
The adversary rules lose nearly twice the recall.
The 29 rules tagged for APT29's own techniques lose a mean of 34.8% of their recall under the coarsening, and 9 of them — 31% — go fully blind, dropping to zero matches. The 25 routine rules lose a mean of 16%, with 4 going blind. The gap between the two, the headline, is 18.8 points of recall loss that falls on the adversary-relevant detections and not on the routine ones.
| Class | Rules | Mean recall-loss | Went fully blind |
|---|---|---|---|
| adversary-tail | 29 | 0.348 | 9 (31%) |
| routine | 25 | 0.160 | 4 (16%) |
| Δ(adversary − routine) recall-loss = 0.188 | |||
The "went blind" column is the security-relevant failure, more than the average is. A rule that loses some recall still fires and still gives an analyst a thread to pull. A rule that goes to zero is a detection the SOC believes it has and does not — it compiles, it runs, it returns nothing, and the coarsening that silenced it left no error behind. Nine of the APT29 rules failed that way under a coarsening they never saw.
Which rules went dark
The detail the coarsening threw away.
The rules that went fully blind are not a random sample, and they cluster on the fields coarsening truncates. Most are PowerShell and process-creation rules that key on the long command line or the script block: base64-encoded PowerShell keywords, malicious script-block content, a screen-capture cmdlet, an uncommon connection to an Active Directory web service. These are the detections that need the exact bytes of what ran, and the coarse store keeps a truncated command line and a sampled rare event, so the field the rule reads is simply not there anymore. The information isn't hidden behind a slow query; it was dropped at ingest, and no amount of compute over the coarse store gets it back.
The routine rules survive for the mirror-image reason. A count of failed logins, a top-N of destination ports, an egress-bytes rollup — none of them depend on the atomic detail coarsening removes, so they come back from the coarse store the same as from the faithful one. The asymmetry is the claim itself, because coarsening is close to free for the queries a compliance report asks while it is ruinous for the ones an incident responder asks.
The number went down
And that is the part to trust.
My original lab testbed, the one where I chose the rules and the attack and the split, reported the gap at about +0.72. The de-gamed test, with verbatim SigmaHQ rules on real APT29 data and the split decided by the rules' own tags, reports it at +0.19. The gap survived being taken out of my hands, which is the result that matters, but it shrank by a large factor once I stopped controlling the levers, and I want to be plain that the smaller number is the more honest one. The lab figure was inflated by exactly the freedom I had to shape it.
I am leading with that drop rather than burying it, because a practice that sells "measured, not asserted" has to show the measurement correcting the assertion, including when the corrected number is less impressive. A gap that holds under a fair test at +0.19 is a real finding, whereas a gap I could only reach at +0.72 by writing my own rules would have been a story, and the difference between those two outcomes is the measurement correcting me rather than flattering me.
Honesty boundary
What it doesn't settle.
This is one synthetic-free but still single dataset on one machine, with 54 fired rules, and APT29 exercises only a subset of techniques, so the population is modest. Recall loss is measured against the faithful store rather than against absolute ground-truth labels, so it captures what the coarsening drops relative to keeping everything, which is the question I'm asking, but not a true-positive rate in the field. The mechanism, that coarse normalization loses the atomic detail adversary detections key on, is near-definitional and well-supported. The in-the-wild magnitude is where I stop short: the coarse store applies a default I documented, and "documented by me" is not "reviewed by someone who runs a security lakehouse at scale." That independent sign-off is the one gate between this and a stronger claim, and it is mine to go obtain.
So I hold the hypothesis at moderate confidence: the mechanism at Tier B on this measurement, the production magnitude at Tier C until the store is independently validated. The fix, where you can afford it, is the hybrid pattern from schema-on-read versus schema-on-write, which keeps the raw somewhere cheap so the coarse analytic store isn't the only copy, and the honest cost of that fix is that you pay to store telemetry you declined to query.
What it means
Decide the grain on purpose.
The practical reading isn't "never normalize." It is that the grain you commit to when you map a source into a single store is a detection decision as much as a storage one, and right now it is usually made by whoever is trying to hold down the bill. When you coarsen the high-volume sources, you are choosing which detections go quietly blind, and on this data those were disproportionately the ones that catch the adversary you most want to catch. The mechanism essay covers how to avoid it field by field; this one is the number that says the cost is real and which detections pay it.
It is the first measured number I know of on a question the field mostly argues about in the abstract. It is not the last one, and the version with an independent practitioner confirming the coarse store is what shops actually build is the stronger test I still owe.