
Implementation anti-patterns
Flattening away your detection logic.
When migrating from SIEM to lakehouse, teams flatten nested JSON to optimize columnar storage. In the process they lose semantic relationships, and detections silently break. The work is semantic translation, not schema conversion. Flattening is the structural face of a larger failure mode the data-modeling world calls context collapse; grain and time are two more faces, and they fail more quietly.
Reading time: 22 minutes. Evidence tier: B–C for the structural patterns (architectural analysis plus practitioner patterns; production case studies pending). The grain and time mechanisms below were Tier D, a thesis and a proposed measurement, until I built the measurement: a reproducible synthetic-corpus benchmark now puts them at Tier B, with the caveats that matter stated where the numbers appear. The full multi-source, priced, independently reviewed version of that benchmark is still the Tier-A target.
V3 update first
Iceberg V3's Variant type changes the fix.
This essay argues that flattening CloudTrail's nested JSON loses critical semantic relationships.
Most notably, the difference between "field absent" and "field is NULL" for
mfaAuthenticated silently broke a privilege-escalation detection. The diagnosis
is unchanged: flattening still loses semantics. What changed is the recommended fix.
The original recommendation was ClickHouse Nested types as the primary architectural answer. Apache Iceberg V3 introduces the Variant type (semi-structured / nested JSON, ratified in Parquet October 2025), purpose-built for exactly this scenario: it preserves JSON absence-vs-null semantics natively, supports queryable nested structures inside a columnar table format, and works across multiple query engines.
For new lakehouse deployments in 2026 and beyond, Variant should be the default for security log types where field presence carries information (CloudTrail, Kubernetes audit, Azure Activity, Okta system logs). ClickHouse Nested remains valid for ClickHouse-only stacks; Variant is the cross-engine answer for Iceberg-based deployments. Both preserve the relationships this essay warns about.
Caveat: V3 Variant engine support is still rolling out across Spark, Trino, DuckDB, and Snowflake
through 2026. Verify your engine supports variant_get() and equivalent semantics before
relying on Variant in production.
The opening case
The migration that broke 23 detections.
A financial services firm migrated 50 TB/day of AWS CloudTrail logs from a commercial SIEM to ClickHouse in December 2024. The team celebrated: query performance improved 10×, infrastructure costs dropped 85%, and analyst complaints about slow searches vanished overnight.
Six weeks later, during a routine SOC 2 Type II audit, the auditor asked: "Show me all IAM privilege escalations without MFA for the past 90 days." The detection engineer ran the query. Zero results.
That couldn't be right. The team manually reviewed CloudTrail logs and found 23 privilege escalation events where users attached IAM policies without multi-factor authentication, exactly the scenario the detection rule was supposed to catch.
The detection logic hadn't failed so much as it had been broken during migration, so it returned empty results instead of alerts, and for six weeks a security control everyone assumed was working was blind.
What went wrong? The migration team flattened CloudTrail's nested JSON structure to optimize
ClickHouse's columnar storage. In the process, they lost a key semantic relationship: in
CloudTrail, the absence of the mfaAuthenticated field means "no MFA," not
"NULL." The flattened schema treated absence as NULL, and the detection rule (checking
WHERE mfaAuthenticated = false) returned nothing.
Why it matters
The flattening tax.
When security teams migrate from traditional SIEMs (Splunk, Elastic) to modern lakehouses (ClickHouse, Iceberg, DuckDB), they face a fundamental architectural trade-off.
Traditional SIEM: stores logs as nested JSON documents, so relationships are
preserved and userIdentity.sessionContext.mfaAuthenticated remains hierarchical. The
semantic meaning stays intact because field presence and absence both carry information, which lets
detection logic express security relationships directly. The weakness is that query performance
degrades at scale, where billions of events turn into 30+ second queries.
Modern lakehouse: stores data in columnar format for compression and speed, and
flattening is common, so
userIdentity.sessionContext.mfaAuthenticated becomes the flat column
userIdentity_sessionContext_mfaAuthenticated. That obscures semantic meaning because the
NULL versus absent versus false distinctions are lost. The strength is 10–100× faster queries and
10–20× better compression; the weakness is that complex hierarchical relationships are harder to
express and easier to break.
The migration from SIEM to lakehouse is a semantic translation that happens to involve schema conversion, and in most of the migrations I've watched the team treats it as the schema problem alone until a detection fails and forces the distinction into view.
Pattern 1
User → session → context → attributes.
Security decisions require context, meaning who did what and under what circumstances, because user identity alone isn't enough and you also need the session context (MFA status, assumed role, source identity).
AWS CloudTrail example:
{
"eventName": "AttachUserPolicy",
"userIdentity": {
"type": "IAMUser",
"userName": "alice@example.com",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2025-02-10T14:23:01Z"
},
"sessionIssuer": {
"type": "Role",
"arn": "arn:aws:iam::123456789:role/AdminRole"
}
}
},
"requestParameters": {
"userName": "bob",
"policyArn": "arn:aws:iam::aws:policy/AdministratorAccess"
}
}
Detection rule: "Alert on IAM privilege escalation (AttachUserPolicy, PutUserPolicy, AddUserToGroup)
by users without MFA." Requires traversing userName → sessionContext → attributes →
mfaAuthenticated, and the semantic that matters is that the field
mfaAuthenticated is only present when MFA was used, so its absence is what tells you no MFA
happened.
The naive ClickHouse translation fails silently:
-- Naive ClickHouse translation (FAILS SILENTLY)
SELECT eventTime, userIdentity_userName, eventName, requestParameters_policyArn
FROM cloudtrail_flat
WHERE eventName IN ('AttachUserPolicy', 'PutUserPolicy', 'AddUserToGroup')
AND userIdentity_sessionContext_attributes_mfaAuthenticated = 'false'; -- Never matches!
When MFA is used the field is present with value "true", but when MFA is not used the
field is absent from the JSON rather than present with "false". The flattened
schema converts that absence to NULL, so the detection query checking = 'false' runs
against a NULL column and matches nothing, which is the silent failure: zero alerts.
The fix: either correct the query semantics or preserve the structure.
-- Approach 1: fix query logic — treat NULL as "no MFA"
SELECT eventTime, userIdentity_userName, eventName, requestParameters_policyArn
FROM cloudtrail_flat
WHERE eventName IN ('AttachUserPolicy', 'PutUserPolicy', 'AddUserToGroup')
AND (userIdentity_sessionContext_attributes_mfaAuthenticated != 'true'
OR userIdentity_sessionContext_attributes_mfaAuthenticated IS NULL);
-- Approach 2: use Nested types
CREATE TABLE cloudtrail_nested (
eventTime DateTime,
eventName String,
userIdentity Nested(
type String,
userName String,
sessionContext Nested(
attributes Nested(
mfaAuthenticated String,
creationDate DateTime
)
)
),
requestParameters Nested(
userName String,
policyArn String
)
);The lesson is that absence carries meaning in security logs, so whatever flattening you do has to preserve the distinctions among NULL, absent, and false rather than collapse them into one.
Pattern 2
Event → action → target → target attributes.
Security detections often filter on action plus target combination: delete a sensitive S3 bucket, modify an admin user, access a PII database table. Flattening can break the association between action and target attributes.
CloudTrail events have 1–N resources (an S3 event touches the bucket plus the IAM user). Flattening
to a single resource_ARN column loses every resource beyond the first. A detection rule
checking "sensitive" in ARN misses events where the S3 bucket sits at index 1 instead of index 0.
Approach 1 (pick first resource only) and Approach 2 (fixed-width array of three) both fail:
-- Approach 1: wrong — loses data
CREATE TABLE cloudtrail_flat (
eventTime DateTime,
eventName String,
resource_ARN String, -- only resources[0].ARN
resource_type String -- only resources[0].type
);
-- Approach 2: wrong — brittle
CREATE TABLE cloudtrail_flat_array (
eventTime DateTime,
eventName String,
resource_ARN_0 String,
resource_ARN_1 String,
resource_ARN_2 String -- what if event has 4 resources?
);The correct approach uses nested arrays:
CREATE TABLE cloudtrail_nested (
eventTime DateTime,
eventName String,
userIdentity_userName String,
resources Array(Tuple(
ARN String,
accountId String,
type String
))
);
-- Query: Alert on DeleteBucket for S3 buckets with "sensitive" in ARN
SELECT eventTime, userIdentity_userName, eventName, resources
FROM cloudtrail_nested
WHERE eventName = 'DeleteBucket'
AND arrayExists(r -> r.3 = 'AWS::S3::Bucket' AND r.1 LIKE '%sensitive%', resources);
A real-world pattern: a SaaS security team used Approach 1 for "simplicity" after migrating
CloudTrail from Elasticsearch to ClickHouse. Detection rule alerting on S3 bucket deletions for
buckets with "backup" or "archive" in the name missed 17 deletion events over 4 weeks, because the
backup buckets were always resources[1] rather than resources[0]. Nobody
noticed until a customer reported missing backups, by which point the four-week blind spot had become
a customer data loss incident and a CISO escalation.
Pattern 3
Process → parent → network → destination.
EDR detection logic chains process execution to network activity ("PowerShell downloads script from external IP," "Office app spawns cmd.exe then connects to C2"). Flattening can break the association between a process and its network connections.
Wrong approach: denormalize (one row per network connection):
CREATE TABLE edr_flat (
eventTime DateTime,
hostname String,
process_name String,
process_pid UInt32,
process_commandLine String,
network_destinationIp String,
network_destinationPort UInt16,
network_destinationDomain String,
network_protocol String
);
-- Result: multiple rows per event (one per network connection)The query "process with HTTP connection to non-CDN" requires aggregation across rows: 45 seconds on ClickHouse versus 3 seconds on Elasticsearch (where the nesting was preserved). PID reuse can mix unrelated processes, generating false negatives.
Correct approach: nested arrays:
CREATE TABLE edr_nested (
eventTime DateTime,
hostname String,
process Nested(
name String,
pid UInt32,
commandLine String,
parentProcess Nested(
name String,
pid UInt32
)
),
network Array(Tuple(
direction String,
protocol String,
destinationIp String,
destinationPort UInt16,
destinationDomain String,
bytesTransferred UInt64
))
);
-- Query: PowerShell with encoded command connecting to non-CDN
SELECT eventTime, hostname,
process.name[1] as proc_name,
process.commandLine[1] as cmd,
arrayFilter(n -> n.2 = 'HTTP' AND n.5 NOT IN ('cloudfront.net', 'akamai.net'), network)
FROM edr_nested
WHERE process.name[1] = 'powershell.exe'
AND process.commandLine[1] LIKE '%EncodedCommand%'
AND arrayExists(n -> n.2 = 'HTTP' AND n.5 NOT IN ('cloudfront.net', 'akamai.net', 'fastly.net'), network);With no aggregation overhead the query executes in under a second on billions of events, so the array denormalization that looked simpler at design time is the thing that breaks performance at scale, while nested types preserve the relationships and run faster.
Pattern 4
Entity resolution across data sources.
Advanced detections correlate user activity across multiple data sources (O365 login + VPN connection + endpoint activity). Entity resolution, mapping the same user across different identifier schemes, requires dimension tables.
O365 sign-in log: userPrincipalName = alice@corp.com. VPN connection log:
username = CORP\alice. EDR process execution:
userSid = S-1-5-21-...-1105. Detection rule: "Alert on O365 login from VPN IP where
endpoint shows suspicious process execution within 5 minutes." Requires correlating all three
identifiers as the same person.
The naive approach joins on mismatched identifiers and fails. The correct approach builds a user dimension table:
CREATE TABLE users (
user_id String PRIMARY KEY,
upn String, -- alice@corp.com (O365)
domain_username String, -- CORP\alice (VPN)
sid String, -- S-1-5-21-...-1105 (EDR)
department String,
manager String,
risk_score UInt8,
mfa_enrolled Bool
);
-- Fact tables reference user_id
CREATE TABLE o365_logins_normalized (
eventTime DateTime, user_id String, ipAddress String, appDisplayName String);
CREATE TABLE vpn_logs_normalized (
eventTime DateTime, user_id String, sourceIp String, assignedIp String);
CREATE TABLE edr_logs_normalized (
eventTime DateTime, user_id String, hostname String, processName String);
-- Query with entity resolution
SELECT o.eventTime, u.upn, u.department, u.risk_score, v.assignedIp, e.processName
FROM o365_logins_normalized o
JOIN users u ON o.user_id = u.user_id
JOIN vpn_logs_normalized v ON v.user_id = u.user_id AND v.assignedIp = o.ipAddress
JOIN edr_logs_normalized e ON e.user_id = u.user_id
WHERE u.risk_score > 6
AND e.eventTime BETWEEN o.eventTime AND o.eventTime + INTERVAL 5 MINUTE;Entity resolution happens once during ingestion, not on every query. The user dimension is small (10K–100K rows), indexed lookups are fast, and 200+ detection rules reuse shared user context. Flattening doesn't directly break cross-source correlation, but the absence of an entity dimension table does. Normalize identifiers at ingest; enrich at query time. One caveat worth naming: which identifier becomes canonical is rarely a technical decision. Joe Reis calls identity resolution a political problem disguised as a technical one, and in a security org that is exactly right. To EDR a "user" is a SID; to IAM an account with entitlements; to a cloud audit log an assumed-role principal three hops from a human. Whose definition wins, and whose asset count changes when you dedupe honestly, are ownership questions the dimension table makes visible rather than resolves.
Pattern 5
Temporal chains (event sequences).
Advanced threats follow multi-step patterns, and the two kinds of temporal chain fail differently. Temporal chains within a single event (authentication attempts) get broken when you denormalize the array, whereas temporal chains across events (lateral movement: RDP → SMB → exec) stay intact in the schema and instead become a query-complexity problem.
Azure AD authentication example with detection rule "2+ failed password attempts followed by successful SMS (MFA bypass indicator)":
-- Correct: nested array preserves sequence
CREATE TABLE azuread_auth_nested (
eventTime DateTime,
userPrincipalName String,
appDisplayName String,
authenticationDetails Array(Tuple(
authMethod String,
succeeded Bool,
attemptTimestamp DateTime
))
);
-- Query: 2+ failed password, then successful SMS
SELECT eventTime, userPrincipalName, appDisplayName, authenticationDetails
FROM azuread_auth_nested
WHERE arrayCount(a -> a.1 = 'Password' AND a.2 = false, authenticationDetails) >= 2
AND arrayExists(a -> a.1 = 'SMS' AND a.2 = true, authenticationDetails);Denormalizing to one row per attempt loses array ordering; the sequence has to be reconstructed via timestamp grouping, which is fragile. Use nested types for within-event sequences.
Pattern 6
Grain: the detail you can't get back.
The five patterns above are all structural: they break when you collapse nested shape into flat columns. The data-modeling world has a name for the larger thing they are instances of. Joe Reis calls it context collapse: the distinctions among who did what, when, where, and what it meant, erased to save space or time. Flattening is the structural face of it, but the next two failure modes are not about structure at all, which is part of why they get less attention, and the first of them is grain.
Grain is the answer to one question: what does one row represent? One row per process execution, one row per netflow record, one row per five-minute summary. There is a near-theorem about it that I have never seen contradicted: you can always aggregate up from fine-grained data, and you can never deterministically disaggregate from coarse-grained data. Roll a thousand connection records into a one-minute-per-host summary and the summary is correct and cheap. It is also a one-way door. The 43-byte beacon to a newly registered domain that repeated every 60 seconds is now indistinguishable from noise inside an average. You cannot get it back from the summary. The information is not hidden; it is gone.
This is a security problem because the economics push hard toward coarse grain, and hardest on the high-volume sources where an intruder hides. Reis concedes the point in a footnote: machine-generated telemetry is the exception to "when in doubt, go finer," because aggressive pre-aggregation is often required to avoid bankrupting your storage budget. A schema-on-read SIEM at a dollar-per-gigabyte-per- day list price turns full-fidelity DNS, netflow, and EDR into a budget line nobody wants to defend. Sampling, coalescing, and summarizing at ingest are the rational responses, and every one is a grain decision that is irreversible at the normalized store.
What makes this matter is the asymmetry between the two kinds of query. Routine queries tolerate coarse grain, since failed logins per user per day is happy at daily grain, but adversary-relevant queries run the other way: lateral-movement reconstruction needs the individual events in order, low-and-slow beaconing needs the inter-arrival timing an average destroys, and living-off-the-land detection needs the specific command line rather than a count of PowerShell runs. So the queries that coarse grain breaks are disproportionately the ones that catch a competent intruder.
I measured that trade on the APT29 evaluation telemetry, the same corpus the grain claim above rests on. Keeping full fidelity, with un-truncated command lines, script blocks, and call traces at atomic grain, cost about 1.8× the storage of a coarsened store over the same ~143,000 events (1.8 MB against 1.0 MB), and the overhead concentrated in exactly the fields whose truncation goes dark on an intruder: the PowerShell script-block column ran roughly ten times larger, the command line about four. So the fidelity that preserves the adversary-relevant recall, which on this corpus runs close to twice the coarse store's, costs under two times the bytes to keep, which is the shape of a false economy where you save a little under half the storage and lose about half the detection that matters, on the high-volume sources where an intruder hides. (Single corpus, one coarsening config; this is the storage side of the bill.)
I have since measured the compute side too, running the same detection battery over both stores, and it tells the same story from the other direction. In aggregate the fidelity store costs only about 1.3× the query time, but that average hides the shape of it, because the premium is concentrated rather than spread: the adversary-relevant detections cost roughly three to four times more to run against full fidelity while the routine ones cost the same, and almost all of that comes from the full-text scans over the un-truncated PowerShell script blocks and command lines. So the compute leg agrees with the recall leg, since the detections that coarsening blinds are the same ones that fidelity makes most expensive to scan, and the ordering a budget should take from this is that storage rather than query-compute is the costly axis of keeping fidelity. (Single corpus, one coarsening config, single host on DuckDB; the queries run in a few milliseconds over ~143,000 events, so the ratios travel further than the absolute numbers do.)
The honest qualifier: irreversible means irreversible at the normalized store. Keep the raw telemetry somewhere cheap and the hybrid pattern from schema-on-read versus schema-on-write recovers what the analytic store dropped. That mitigation is real and not free, since you are paying to store raw you declined to query. The grain problem does not vanish; it becomes a question of whether you will pay twice.
Pattern 7
Time: which of the timestamps did you keep?
Pattern 5 was about ordering within a single event. This one is a layer up: a single security event
carries several kinds of time, and collapsing them is its own species of context collapse.
Reis separates four. Event time is when it happened in the world. Ingestion time is when it reached
your system. Processing time is when your pipeline worked on it. Valid time is the period a fact was
actually true. They diverge constantly: a laptop goes offline, its EDR buffers, and an hour of events
whose event time is 14:00 arrive with an ingestion time of 15:10. OCSF gives you distinct fields
(time, observed_time, and friends). A pipeline under deadline gives you one
populated time column and moves on.
Cross-source attack reconstruction is an ordering problem, and you can only order by event time. If your EDR normalized to processing time and your firewall normalized to ingestion time, a timeline that reads "process spawned, then outbound connection, then authentication on the target" is built from three clocks that never agreed. The sequence looks plausible and is wrong, which is the worst failure a timeline can have: an analyst builds an incident narrative on it, and the narrative is fiction that survives review because nothing in it looks broken.
There is a smaller version that costs nothing to fix and is wrong everywhere. A timestamp without a
zone offset is a floating timestamp. 2026-03-30 14:30:00 logged in Frankfurt and read in
Virginia is two moments six hours apart, and your "events within five minutes" correlation window
silently spans the Atlantic. Store UTC with the Z, keep the original zone in its own
field, and name columns for the kind of time they hold (event_time,
ingest_time, valid_from) rather than calling everything timestamp.
The advanced version is bitemporality: tracking both when a fact was true and when your system came to believe it. For detection engineering that is a luxury. For the post-incident question of what the SOC could have known at decision time, it is the difference between an honest retrospective and a flattering one.
There is a deeper version of the plausible-but-wrong trap, and it lives below the parsed layer entirely. Reviewing the raw, unparsed depths of a dataset once, I found what looked like Chinese characters buried in the bytes, which turned out to be a Windows encoding artifact, mojibake from a code page the pipeline had misread, not literal Chinese at all. A hunter watching asked how I'd even done that, because going into the unparsed depths and reading an encoding gotcha correctly is a skill almost nobody practices once everything arrives pre-normalized. Two lessons fall out of it. The truth often sits below the normalized view, in the depths the detections never look at, and a misread of those depths manufactures false signals as readily as it hides real ones: those "Chinese characters" could have seeded a confident and entirely wrong attribution to a Chinese actor when the real cause was a character set. Ground against the actual bytes rather than the normalized assumption, and you surface both the hidden signal and the false one.
When to flatten vs. preserve.
The useful question is rarely "should I flatten?" but rather which fields you can safely flatten without breaking detection logic.
Flatten to columns when
- Field is always present (not optional).
- 1:1 relationship (one value per event, not an array).
- No semantic dependency on field presence (NULL = missing data, not "false").
- Query pattern is simple filters (
WHERE field = value). - High query frequency (80%+ of queries touch these fields).
Preserve as nested/array when
- Variable-length arrays (0–N elements).
- Hierarchical structure with semantic dependencies.
- Field presence is meaningful (absence ≠ NULL).
- Detection logic depends on array ordering or grouping.
- Query pattern is "ANY element in array matches condition."
Use dimension tables when
- Entity data (users, hosts, services) referenced across many log types.
- Reusable context (attributes change infrequently).
- Slowly-changing dimensions (weekly, not per-event).
- JOIN overhead acceptable (query latency measured in seconds).
Solutions
Architectures that preserve both performance and relationships.
Solution 0: Iceberg V3 Variant type (recommended for new deployments)
For semi-structured logs where field presence carries information (CloudTrail, Kubernetes audit, Azure Activity, Okta system logs), and for multi-engine query environments, this is now the preferred answer. Iceberg V3 (with Parquet's matching Variant type, ratified August 2025) introduces a native semi-structured column type that preserves JSON's absence-vs-null distinction, supports queryable nested structures, and works across all engines that adopt V3 (Spark, Trino, DuckDB, Snowflake; engine support rolling out through 2026). Unlike ClickHouse Nested, Variant is engine-portable.
CREATE TABLE cloudtrail_v3 (
eventTime TIMESTAMP,
eventName STRING,
userIdentity VARIANT, -- preserves the entire nested userIdentity object
requestParameters VARIANT,
sourceIPAddress STRING,
awsRegion STRING
) USING iceberg
TBLPROPERTIES ('format-version' = '3');
-- Detection rule: still works, semantics preserved
SELECT eventTime,
variant_get(userIdentity, '$.userName', 'STRING') as userName,
eventName
FROM cloudtrail_v3
WHERE eventName IN ('AttachUserPolicy', 'PutUserPolicy', 'AddUserToGroup')
AND variant_get(userIdentity, '$.sessionContext.attributes.mfaAuthenticated', 'STRING') IS NULL;
-- IS NULL correctly captures "field absent = no MFA"
Pros: cross-engine portable; preserves field-absence semantics by construction; no per-engine learning
curve; future-proofed. Cons: engine adoption uneven through 2026 (verify your query engine supports
variant_get and Variant-aware predicate pushdown); fewer production references than
ClickHouse Nested or Hydrolix.
Solution 1: ClickHouse Nested types
Still valid for ClickHouse-only stacks. Relationships preserved, performance nearly as good as flat columns, production-validated at Netflix scale (tag sharding 3s → 700ms). Trade-offs: Nested syntax learning curve, limited JOIN support on arrays, ClickHouse-specific.
CREATE TABLE cloudtrail_nested (
eventTime DateTime,
eventName String,
userIdentity_userName String,
resources Nested(
ARN String,
type String
)
) ENGINE = MergeTree()
ORDER BY (eventTime, eventName);
SELECT eventTime, userIdentity_userName, eventName
FROM cloudtrail_nested
WHERE eventName = 'DeleteBucket'
AND arrayExists(r -> r LIKE '%sensitive%', resources.ARN)
AND arrayExists(t -> t = 'AWS::S3::Bucket', resources.type);Solution 2: Hybrid architecture (hot flat + cold nested)
For mixed workloads (80% simple aggregations, 20% complex forensics):
Logs → Kafka → Dual-Write
├─→ ClickHouse Hot Tier (Flattened, 7–30 days)
└─→ Iceberg Cold Tier (Nested, 90–365 days)
Query Router:
- Time < 30 days → ClickHouse (sub-second, flattened)
- Time > 30 days → Trino + Iceberg (5–10 seconds, nested)Benefits: performance for recent data, structure for forensics, cost-optimized. Trade-offs: dual maintenance, storage duplication during overlap window.
Validation checklist
Before you flatten.
Schema validation
- Document all optional fields (presence/absence meaningful vs NULL).
- Map all array fields.
- Document hierarchical relationships.
- Flag fields where NULL ≠ absent ≠ false.
Detection logic validation
- Export all detection rules from current SIEM.
- Translate each rule to lakehouse SQL.
- Test translated rules on sample data.
- Validate results match SIEM.
Parallel run
- Dual-write to SIEM and lakehouse for 30+ days.
- Run detection rules in both systems.
- Compare alert volume (zero missed detections).
- Validate alert parity achieved.
Performance vs. correctness
- Measure query latency: flat vs nested.
- Decide: is 2–5× slower acceptable to preserve relationships?
- Priority: correctness over performance. Missed detections are unacceptable.
The measurement
How you'd prove the grain/time claim wrong.
The structural patterns above are backed by concrete failures. The grain and time argument is, for now, a mechanism and a claim: that the loss falls disproportionately on adversary-relevant queries rather than uniformly. I cannot assert that from first principles, and I am suspicious of anyone who would. It needs a number. Here is the benchmark I think settles it, including the parts designed to keep me honest, because I have an obvious incentive to want it to be true.
Take one multi-source corpus with a planted, ground-truthed attack chain (EDR, network, identity, cloud audit), where the true event-time ordering and the true host-to-user-to-principal links are known. Build two stores from the same raw. The first is a single normalized OCSF store at a realistic, volume-driven grain, the kind a real pipeline produces under cost pressure: coalesced, one time field populated, identity flattened for joins. The second preserves fidelity: atomic grain, all four time types, observables and domain tags intact. Run one query battery, split and pre-registered before either store is built so I cannot tune the queries to the result. The routine half is counts, top-N, and simple filters. The adversary half is timeline reconstruction across sources by true event time, cross-domain identity closure, and who-did-what-when-where path queries.
The headline statistic is one difference: the degradation on the adversary half minus the degradation on the routine half. A large positive number supports the claim. A number near zero supports the null, the genuinely possible outcome that a well-built OCSF pipeline (multiple time fields populated, observables intact, raw retained) shows no adversary-biased gap at all. In that case the honest reading is that I was describing lazy normalization, not OCSF normalization, and I would report it without softening. Three guardrails make the test worth running: the normalized store derived from a real OCSF pipeline default rather than a strawman; the fidelity-preserving store priced, since keeping the finest grain hot carries the storage bill that drove normalization in the first place; and an independent practitioner who has run a security lakehouse at scale confirming the normalized store resembles what shops actually build.
I tracked this as a low-confidence, falsifiable hypothesis, and the section that follows is the first run at turning it into a finding. If the gap is real and survives the guardrails, it is the first measured number on a question the field argues about entirely in the abstract. If the gap is not there, that is worth knowing too, and cheaper to learn from a benchmark than from a missed intrusion.
The measurement — first result
What the first run found.
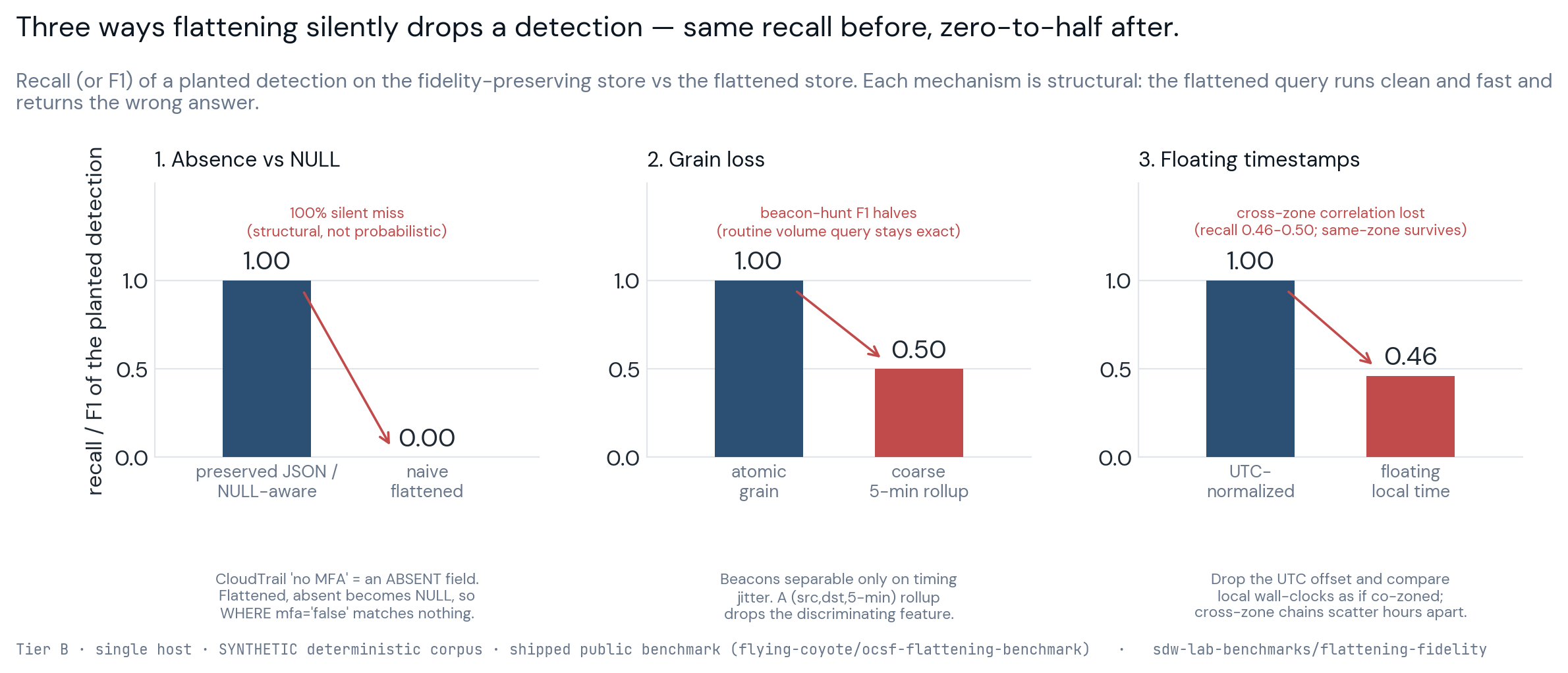
The section above is the test I said I'd run, so I built a first version of it and put it in a public repository you can clone and re-run. It is not yet the full single-corpus battery with the priced fidelity store and the independent practitioner sign-off; it is the smaller, honest start. Three controlled synthetic corpora, one per mechanism, each scored against a ground truth I planted, with the same detection logic run over a lossy schema and a fidelity-preserving one. DuckDB stands in for the engine and Variant-style JSON stands in for the preserved store, and every number is reproducible, because the suite runs twice and checks the output is byte-identical before it prints, and two separate processes produced the same results digest.
The absence-vs-NULL case is the cleanest, because it is not probabilistic. Plant privilege-escalation
calls made without MFA, flatten the column so the absent mfaAuthenticated becomes NULL,
and the naive translation that checks = 'false' recovers none of them: zero of 141 at a
thousand events, zero of 14,140 at a hundred thousand. The preserved schema and a NULL-aware query
recover all of them. That is the opening case study's bug reproduced as a measurement rather than an
anecdote, and the miss is 100% by construction, because once the column is flattened, absent and NULL
are the same byte.
Grain is where I most wanted to be wrong, since I have an obvious incentive to find the gap I predicted. I planted beacons at a regular sixty-second interval and benign decoys with the same per-bucket volume and the same forty-three-byte payload, bursty within the bucket, so the only thing separating malice from noise is inter-arrival timing. At atomic grain a jitter test separates them perfectly, at F1 1.00. Rolled up to a five-minute (source, destination) grain the individual timestamps are gone, the fair-effort detector falls back to steadiness of per-bucket counts, and it can no longer tell the beacon from the decoy: F1 drops to 0.50 while the volumetric routine queries, bytes per host and connection counts, come back exact to the row. That asymmetry is the whole claim, since the rollup is free for the routine half and ruinous for the timing-dependent adversary half.
The floating-timestamp case is the quiet one. Cross-source chains that are genuinely within a five-minute window in UTC, with their sources sitting in real timezones, correlate perfectly when the offset is preserved and lose exactly the cross-zone half when it is not, so recall drops from 1.00 to roughly 0.46–0.50 at a cross-zone mix near half, and the same-zone chains still look right, which is why nobody notices. I want to be careful about what these numbers are and are not. The grain F1 and the floating recall are not universal constants, they track the corpus I built, and they track it in a way I can write down: the grain F1 is 2 / (2 + decoy-to-beacon ratio) exactly, so the 0.50 is just the ratio-of-two point, and the floating recall is 1 minus the cross-zone fraction, so the 0.46–0.50 is the half-cross-zone point — change the ratio or the cross-zone mix and the lossy number slides along that curve while the preserved store stays pinned at 1.00. So the honest reading is directional, a controlled demonstration of the mechanism rather than a production rate, and the methodology file says so in as many words. Only the absence result is structural enough to quote without that hedge.
So the grain and time claims move from Tier D to Tier B: reproducible and first-party, but synthetic and controlled, not a production measurement. The version that would earn Tier A is still the one in the section above, with one real multi-source corpus, the fidelity-preserving store priced against the storage bill that drove normalization in the first place, and an independent practitioner who has run a security lakehouse confirming the lossy store resembles what shops actually build. This is the first number on a question the field argues about in the abstract; it is not the last one.
There's a second, quieter pressure toward flattening that isn't about information loss at all, and I
measured it the same way. Keep the nested OCSF shape — the endpoint structs and the
observables[] list-of-structs — and the open read contract holds only one level deep.
Across DuckDB, DataFusion, chDB, and Polars, scalar struct access (dst_endpoint.port) and
list length read identically, but the natural observables question, "does any observable carry this
type", isn't portable: DuckDB, chDB, and Polars each express it and agree, while DataFusion can't apply
a per-element struct-field predicate in a WHERE clause at all. So an open table format guarantees every
engine can read the bytes, not that every engine can ask the same nested question the same way, and that
gap at the list-of-struct boundary is a measured reason teams flatten observables[] into
their own columns before querying. Flattening trades the schema fidelity this essay spends its length
defending for query portability, so the honest position is that both costs are real and the decision is
which one you'd rather pay.
Takeaways
The flattening tax is real.
Flattening is a semantic translation carried out through schema conversion, so the relationships between fields end up mattering as much as the values inside them.
- Absence is meaningful in security logs. MFA field absent equals no MFA, not NULL. Flattened schemas must preserve semantic distinctions.
- Arrays are common in security data. CloudTrail
resources[], EDRnetwork_connections[], Azure ADauthenticationDetails[]. Denormalizing breaks relationships and performance. Use nested types, or Iceberg V3 Variant. - Test correctness, not just performance. Parallel runs must validate alert parity. If SIEM produces 1,250 alerts/week and lakehouse produces 1,248, investigate the missing two. Slow and correct beats fast and wrong.
- Hybrid architectures balance trade-offs. Hot flat plus cold nested solves the 80/20 problem. 80% of queries hit recent data with simple filters (sub-second, flattened). 20% hit historical forensics (5–10 seconds acceptable, nested).
- Document relationship dependencies before flattening. Map detection logic dependencies first. Schema translation comes second. Teams that focus on schema mapping miss semantic dependencies and break detections.
- Grain and time fail more quietly than structure. A broken JSON path is at least loud. Choosing a coarse grain or keeping the wrong timestamp fails silently, and the queries it breaks are disproportionately the adversary-relevant ones. When you map a source into OCSF, decide deliberately what grain you are committing to and which timestamp you are keeping, not just which field goes where. Whether that loss is real and adversary-biased was a Tier-D claim; the benchmark above now measures it at Tier B, with the coarse rollup answering volumetric routine queries exactly while a beacon hunt that depends on inter-arrival timing lost half its F1, and the full priced, multi-source version still the stronger test I owe.