
OCSF adoption
Six schemas into OCSF: the mapping is the hard part.
What field-level mapping of Splunk CIM, Google Chronicle UDM, Microsoft Sentinel ASIM, Elastic ECS, OpenTelemetry, and Zeek into OCSF 1.8.0 reveals about the standard's real adoption cost, and its own limits.
What this is based on: six field-level crosswalks I built against OCSF 1.8.0, one per source, for Splunk CIM 6.0, Google Chronicle UDM, Microsoft Sentinel ASIM, Elastic ECS 9.4.0, OpenTelemetry, and Zeek. Every source field routes to an OCSF attribute path, every path validated against the public OCSF schema and real mapper fixtures (Cisco ASA→OCSF JSON on the network classes). The Zeek mapping is my own open-source contribution: executable mapping logic running at the sensor, validated on real packet capture rather than a paper field table.
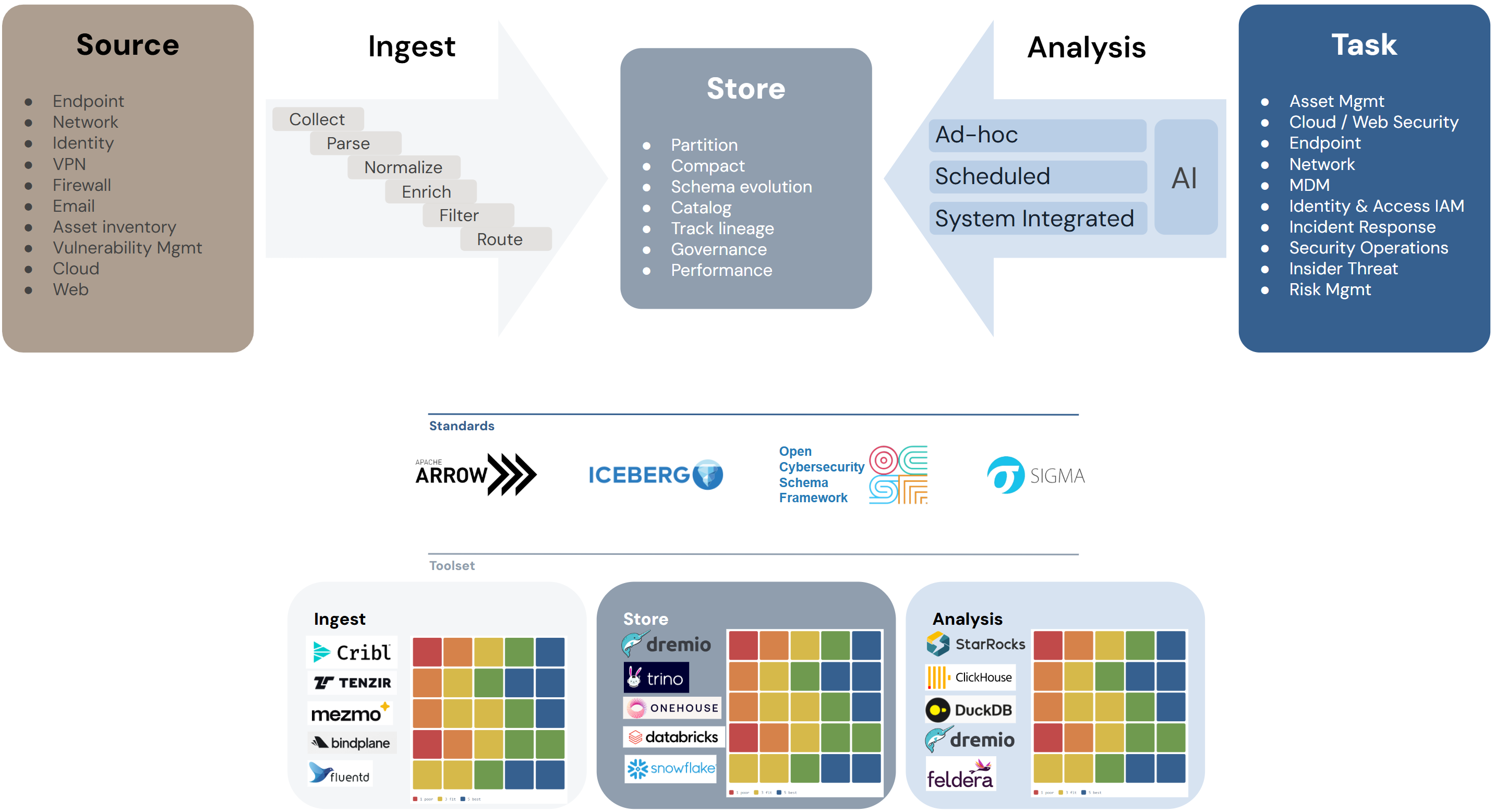
Adoption of the Open Cybersecurity Schema Framework rarely stalls at the question the debates fixate on, because teams don't spend their political capital arguing whether OCSF is a good idea; most of them already accept that a shared event schema beats a thousand private ones. The work dies one step later, at mapping — the unglamorous job of getting your sources into OCSF field by field, with the enum bridges and the lossy edges and the required attributes your logs never carried. That is the step where the standard meets the actual data, and it is where the people who define OCSF and the people who have to adopt it stop speaking the same language.
I spent the past stretch doing that job in the open, against OCSF 1.8.0, for six source schemas: Splunk's Common Information Model 6.0, Google Chronicle's Unified Data Model, Microsoft Sentinel's Advanced Security Information Model, Elastic Common Schema 9.4.0, OpenTelemetry's logs data model and semantic conventions, and Zeek. Each got a field-level crosswalk in which every source field is routed to an OCSF attribute path, every mapping carries a confidence label, and every lossy seam is named rather than smoothed over, and I checked the attribute paths against the published 1.8.0 schema and, for the network classes, against the JSON a real mapper actually emits. What came out is less a set of lookup tables than a map of where normalization is clean, where it collapses, and why — and the why turns out to be more about OCSF than about any of the six sources.
The architecture spectrum
The sources arrange themselves by architecture.
If you put the six sources on a line by how they are built, the mapping difficulty falls out of the architecture before you map a single field.
At one end sits Splunk CIM, which is flat, search-time, and alias-based: a CIM "data model" is just a
set of field names that any sourcetype can claim by tagging itself, so a logon and a firewall deny end
up in the same flat namespace of src, dest, user, and
action. CIM is the hardest source to map well, and not because Splunk did anything wrong,
but because the model is twenty years of pragmatic search convenience and it happens to make the
structural assumptions OCSF does not. CIM carries no severity on most of its models, so OCSF's required
severity_id has to be invented for something like two-thirds of the telemetry; its single
action field conflates what happened with what the policy decided; and
its flat src_*/dest_* namespace has to be lifted into OCSF's nested
src_endpoint and dst_endpoint objects. Mapping CIM to OCSF is mostly a
sequence of judgment calls, which is exactly the thing you cannot encode once and then trust.
Microsoft's ASIM sits in the middle, and it is the most interesting of the six because it is a genuine
hybrid. It keeps CIM's flat, prefixed field names (SrcIpAddr, TargetUsername,
DvcAction), so the flat-to-nested lift comes back, but it normalizes everything CIM left
raw, carrying a native EventSeverity, splitting operation (EventType) from
verdict (DvcAction), pre-splitting vendor and product, and typing its hashes per
algorithm. So ASIM pays CIM's mechanical tax while escaping CIM's judgment taxes, and it adds one move
neither neighbor makes: it tags the type of every identifier — whether a user ID is a
SID, an Okta ID, an AWS ID, or an Entra object ID — which is actually richer than OCSF can
represent, so that provenance falls into the unmapped bag on the way in.
At the far end are two schemas that share OCSF's own DNA. Google Chronicle's UDM and Elastic's ECS are
both typed, nested, and built in the same era for the same purpose as OCSF, and they are the easiest
on-ramps by a wide margin. UDM hands you severity_id natively on every event, which is the
gap CIM forced you to invent, and ECS goes one better on classification, because its
event.kind / event.category / event.type /
event.outcome quartet is the cleanest routing key of any source I mapped and it
pre-declares which event types are legal for each category, so the classification both routes the event
to an OCSF class and validates it at the same time. If I had to stand up a green-field OCSF pipeline
tomorrow I would start from UDM or ECS, and the crosswalks say so in field-level detail.
OpenTelemetry is not really on this line at all, and saying that plainly is half the value of having
mapped it. OTel is an observability transport with a semantic-convention registry alongside it, so it
has no security event taxonomy and no field that says what kind of event a record is, which
means mapping it to OCSF is two jobs stacked together: an envelope mapping that takes the logs data
model (SeverityNumber, Timestamp, Resource) onto OCSF's
class-agnostic spine, plus an attribute mapping that takes the network.*,
http.*, and process.* semantic conventions (many of them inherited from ECS,
after Elastic donated it to OpenTelemetry) onto OCSF objects, with the entire class-selection problem
left unguided in between. OTel will tell you that a connection happened and how severe the log line
was, but it will not tell you whether you are looking at a network event, an authentication, or a
detection, and that unguided gap is itself one of the more interesting findings.
Zeek is the sixth, and the one that taught me the most, partly because I built and open-sourced its
OCSF mapping myself. Zeek is connection-centric rather than event-centric: it emits one record per
protocol transaction across a dozen log files — conn.log, dns.log,
http.log, ssl.log, files.log — all stitched together by a
shared connection uid, and it is the only source in the set backed by executable mapping
logic that runs at the sensor and is validated on real packet capture rather than on a paper field
table. Its base logs carry no severity and no verdict, because Zeek's job is observation rather than
adjudication, and only notice.log, its alerting layer, produces anything that maps to a
finding, so the crosswalk ends up being a fairly precise picture of what a network sensor's view of the
world can and cannot see.
The empty cells
Reading the gaps in the matrix.
If you lay all six mappings against OCSF as the spine, with OCSF attributes down the rows and the six sources across the columns and each cell holding that source's corresponding field, the table tells you more by what is missing than by what is filled, which is why that field-centric matrix is the one artifact I would put in front of someone deciding whether OCSF is worth the cost.
The emptiness comes in two kinds that mean opposite things. Some cells are empty because a source is blind: Zeek's columns for the authentication, process, and account-change classes are empty all the way down, because a passive network sensor cannot see a logon, a process launch, or an IAM change, and that is honest blindness you would never have asked Zeek to cover in the first place. OpenTelemetry's authentication column is nearly as sparse, for the deeper reason that OTel has no authentication semantics to offer.
The other kind of emptiness is the one that matters, because some rows are empty across every source, and once a row is blank for all six it has stopped telling you anything about the sources and started telling you about OCSF.
Key visual
Network Activity (4001), six sources against one OCSF spine.
Here is one class of the field matrix. OCSF Network Activity, class_uid 4001, is the
spine; each column is one source; each row is one OCSF attribute, with the source's corresponding
field in the cell. A — means the source has no field for that OCSF attribute, so
the column cannot reach that part of OCSF. A trailing ~ flags a low-confidence or
inferred mapping. Required attributes are marked req. Read across a row to see how
the six sources each reach (or fail to reach) the same field; read down a column to see how much of
the class a source can populate. These network mappings are fixture-validated against
Cisco ASA→OCSF JSON.
| OCSF attribute | Splunk CIM | Google UDM | Microsoft ASIM | Elastic ECS | OpenTelemetry | Zeek |
|---|---|---|---|---|---|---|
activity_id req | action (enum) | security_result.action (enum) | DvcAction+EventSubType (enum) | event.type (enum) | — (default Traffic) | conn_state (enum)~ |
severity_id req | — | security_result.severity (enum) | EventSeverity (enum) | event.severity~ | SeverityNumber (enum) | — (invent) |
time req | _time | metadata.event_timestamp | EventStartTime | @timestamp | Timestamp (ns→ms) | ts (s→ms) |
metadata req | vendor_product (split) | metadata.product_name/vendor_name | EventProduct/EventVendor | observer.* | Resource/EventName | Zeek/Corelight (construct) |
src_endpoint or dst_endpoint req | src/dest | principal.*/target.* | Src*/Dst* | source.*/destination.* | source.*/destination.* | id.orig_*/id.resp_* |
category_uid / class_uid req | const | const | const | const | const | const |
src_endpoint.ip | src/src_ip | principal.ip | SrcIpAddr | source.ip/source.address | source.address / client.address~ | id.orig_h |
src_endpoint.port | src_port | principal.port | SrcPortNumber | source.port | source.port~ | id.orig_p |
dst_endpoint.ip | dest/dest_ip | target.ip | DstIpAddr | destination.ip/destination.address | destination.address / server.address~ | id.resp_h |
dst_endpoint.port | dest_port | target.port | DstPortNumber | destination.port | destination.port~ | id.resp_p |
connection_info.protocol_name | transport/protocol | network.ip_protocol (enum) | NetworkProtocol (enum) | network.transport/network.iana_number | network.transport~ | proto (+derive num) |
connection_info.direction_id | direction (enum) | network.direction (enum) | NetworkDirection (enum)~ | network.direction (enum)~ | network.io.direction~ | local_orig/local_resp (derive)~ |
connection_info.uid | session_id/flow_id | network.session_id | NetworkSessionId | network.community_id~ | — | uid (join key) |
connection_info.community_uid | — | — | — | network.community_id~ | — | community_id (1:1) |
traffic.bytes_in | bytes_in | network.received_bytes | DstBytes | destination.bytes | — (in metrics) | resp_bytes |
traffic.bytes_out | bytes_out | network.sent_bytes | SrcBytes | source.bytes | — (in metrics) | orig_bytes |
status_id | action~ | security_result.action~ | EventResult~ | event.outcome~ | — | — |
duration | duration (×1000) | network.session_duration (×1000) | NetworkDuration | — | — | duration (×1000) |
firewall_rule.uid / .name | rule~ | — | NetworkRuleName/NetworkRuleNumber | rule.name/rule.id~ | — | — |
src_endpoint.intermediate_ips[] | src_translated_ip~ | intermediary.ip/.hostname~ | SrcNatIpAddr~ | source.nat.ip/.port~ | — | — |
device | dvc/dvc_ip~ | observer.ip/.hostname / intermediary.*~ | Dvc~ | host.*~ | Resource → host.* | — |
The unmapped tail for this class, the meaningful source fields that have no OCSF home at all and land
in unmapped / enrichments:
- CIM:
src_translated_ip/src_translated_port/dest_translated_ip/dest_translated_port(NAT — no OCSF symmetric pre/post pair);*_zone(src_zone/dest_zone/dvc_zone— admin labels, not the fixedboundary_idenum). - UDM:
network.parent_session_id(no first-class parent-session link);BROADCAST/MULTICASTdirection (no OCSFdirection_idslot); NAT context (intermediarycleaner on input, still no OCSF pair). - ASIM:
SrcNatIpAddr/DstNatIpAddr/*NatPortNumber(NAT, no OCSF pair);SrcZone/DstZone/DvcZone;Local/Externaldirections (no OCSF slot);Encrypt/Decrypt/VPNrouteDvcAction(belongs in Tunnel Activity 4014). - ECS:
source.nat.*/destination.nat.*(NAT, no OCSF pair);observer.ingress.zone/egress.zone; over-richnetwork.direction(7 values → OCSF's 4,externalcollapses); multi-valuedevent.category/event.typeoverflow (["network","session"]);network.community_idwhen it can't claimconnection_info.uid. - OTel:
TraceId/SpanId(trace context);client.*/server.*second coordinate system (vantage vs packet-direction); byte/packet counters (live in OTel metrics, not log/span attributes); no flow lifecycle (Open/Close/Reset have no OTel source); no verdict/zone/NAT (OTel isn't a firewall). - Zeek:
history(per-packet flag-history stringShADadFf— no OCSF native, lands inconnection_info.history/unmapped);conn_statenuance beyondactivity_id(the 13-state TCP vocabulary collapses to 7 lifecycle slots, so the orig-vs-resp-aborted distinction RSTO/RSTR survives only instatus_detail);local_orig/local_resp(the local/remote pair derives direction but has no symmetric OCSF home);orig_ip_bytes/resp_ip_bytes(IP-layer counts vs OCSF's payload-onlytraffic.bytes);missed_bytes(capture-loss counter). The seam Zeek alone carries: the cross-loguidre-stitch — conn/dns/http/ssl rows share auid→connection_info.uidbut OCSF holds them as separate events with no native re-assembly, so reconstructing one flow is the consumer's query-time job.
This is one class of seven. The full matrix spans Authentication (3002), Network Activity (4001), HTTP Activity (4002), Process Activity (1007), File System Activity (1001), Account Change (3001), and Detection Finding (2004), each with its own column-by-column table and unmapped tail.
The five seams
The seams that keep recurring.
Five seams kept recurring as I worked through the crosswalks, mostly independent of which source I was mapping, and together they were the most useful thing the six produced, because they are not bugs in CIM or gaps in UDM so much as the shape of OCSF 1.8.0 itself.
The first is severity, and it is the cleanest illustration of the pattern. OCSF makes
severity_id a required attribute on its authentication, network, HTTP, process, and
detection classes, but severity is a judgment a source either makes or it doesn't: CIM doesn't, on most
models, so you invent it; ECS technically has an event.severity field, but it is a
source-defined integer with no controlled vocabulary, so you are inventing again with only a number to
anchor to; ASIM gives you four buckets and no "critical," while UDM gives you the full range natively.
In the Cisco ASA output I validated the network mappings against, a denied connection had been assigned
severity_id 5, Critical, while the allowed connections came through as Informational, and
that assignment was the mapper author's convention rather than anything the firewall actually reported,
so the same required field arrives free from one source, coarse from another, and fabricated from a
third, which means the severity on an OCSF event can tell you as much about the mapper as about the
threat and the downstream consumer has no way to know which.
The second seam inverts the usual direction of loss, which is why I keep coming back to it. OCSF's
network, HTTP, process, and file activity classes have no disposition_id, so there is no
first-class place to record whether the firewall allowed or blocked, whether the proxy permitted or
denied, or whether the EDR quarantined, even though that verdict is the single field a SOC analyst
filters on and these are the busiest event classes in the schema. UDM, ASIM, and ECS all separate the
verdict cleanly from the operation, which hands the mapper exactly the thing OCSF cannot receive, so the
cleanest-modeled sources carry their verdict all the way to the destination and then lose it there.
Disposition lives only on the findings classes, which is part of why deny-heavy firewall and proxy
telemetry sometimes reads better as a detection than as the network event it actually is, a modeling
contortion that the missing field quietly forces on you.
The third seam is change, and it starts from the fact that there is no single OCSF "change" class. An
account modification, a group-membership edit, a registry write, and a policy update scatter across
Account Change, Group Management, Entity Management, Device Config State Change, and the registry
classes, so every source that logs "something was modified" has to be routed into the right class by
reading a sibling field, and that routing is the seam. CIM routes on a free-string
object_category that varies by vendor, which is guesswork, whereas UDM, ASIM, and ECS route
on closed enumerations, which is reliable, but none of them escapes the fact that OCSF deliberately
decomposed what those sources kept as a single surface, and the decomposition is now the adopter's
problem.
The fourth seam is mechanical but relentless, and it is the flat-to-nested lift. Flat sources like CIM
and ASIM name their fields src_ip and SrcIpAddr, and OCSF wants them nested
inside src_endpoint, actor, and user objects, while nested
sources skip the lift entirely because ECS's source.ip becomes src_endpoint.ip
as a rename rather than a restructure, so the same content lands as the difference between an afternoon
and a week of mapper engineering, decided by an architectural choice the source made years before anyone
thought about OCSF.
The fifth seam is the subtlest, and ASIM is the one that surfaced it: identifier provenance. OCSF gives
you user.uid and user.sid as separate typed attributes, but it has no general
way to record which directory issued an identifier, whereas ASIM tags every ID with its type
— SID, Entra object ID, Okta ID, AWS ID — and ECS makes similar distinctions, so OCSF
flattens all of them back into user.uid and the provenance drops into the unmapped bag.
Here the source is richer than the standard and the mapping loses information on the way up,
which is the reverse of the loss you normally expect from normalization, and it is worth saying out loud
because it complicates the tidy story that mapping into a richer schema is always a gain.
Zeek added a sixth that the SIEM schemas never raised, because its whole model rests on the connection
uid that stitches a flow's records together across log files, and OCSF's
one-event-per-record model has no first-class cross-event key. You can map uid to
connection_info.uid and preserve the value, but re-stitching the flow — reassembling
the DNS lookup, the TLS handshake, and the HTTP request that all belong to one connection —
becomes the consumer's problem. Zeek also exposed OCSF's missing certificate class, because its
x509.log describes a certificate seen on the wire and OCSF models certificates as an object
that has to ride inside some other event with no class of its own, which is a genuine gap in the
standard and the kind of thing worth taking upstream rather than mapping around.
I had derived those seams by reading crosswalks rather than running them, so to test whether they were real or just a tidy story I put two sources I had not mapped before, Okta's System Log and CrowdStrike's detection stream, through a small benchmark that scores every documented field into OCSF 1.8.0 as typed, coerced, or unmapped, with each target validated against the published schema so that a mapping cannot invent a home that is not there. The same seams came back. Okta's login event lands 58% of its fields on a typed attribute and loses the other 42% to coercion or the unmapped bag, and what it loses is what the seams predict: the seven-value outcome enum narrowing to three, the risk and threat signals sitting in a free-form map OCSF has no typed home for, the proxy chain flattening to a bare list of IPs, and the anonymizing-proxy flag that OCSF's endpoint object does not carry at all. CrowdStrike's detections map better, at 70% typed, because file hashes and command lines are well modeled, but its ATT&CK tactic and technique arrive as flat strings where OCSF wants an id and a name both, and its multi-action response bitmask collapses to a single disposition.
What the running version showed that the paper ones could not was the distance between what the schema allows and what a shipped mapper does. OCSF 1.8.0 has a typed or coercible home for 36 of Okta's 50 login fields, but Okta's own open-source reference mapper carries only 18 of them into the event, leaving the autonomous-system, ISP, and credential-type fields, all of which feed real detections, unmapped even though the schema would hold them. So the seam is in the standard and also in the gap between the standard and the integration, and that second gap, which the benchmark now measures, is the expert-gating this piece is about. The benchmark, its per-field mappings, and the twenty-three of thirty-one named detections that lose a field they depend on are in the SDW Lab ocsf-mapping-fidelity benchmark.
A second mapper made the same point from the other side, and it is the cleaner example because it is the
shipped one for the source I know best (Tier B, single host, synthetic corpus; Tenzir 6.0.0, library
commit 671e049, against OCSF 1.8.0). I ran Tenzir's published zeek::ocsf::map
unedited over a seeded Zeek conn corpus, and on the surface it does the job: it picks the
right OCSF class on every record (100%, Network Activity 4001) and lands most of the values it carries
(92%). Field-level scoring stops there and would call that a pass, but it does not derive
activity_id from Zeek's conn_state, so the activity classification — open
versus close versus reset versus fail, the very thing a consumer filters connections on — is wrong
on 83% of records, and a few fields like history, service, and the connection
uid fall into unmapped rather than a typed home. The harder number is the one
next to it: of the four common sources I tried (Zeek, CloudTrail, Sysmon, generic auth), the shipped
library produces a usable OCSF mapping for exactly one. There is no CloudTrail-management-events operator
in the shipped Amazon package, the Sysmon mapping expects raw Windows EVTX/XML and refuses the
pre-parsed JSON most EDR shippers carry, and a generic auth source has no mapping at all. So "maps to
OCSF" turns out to be a coverage claim and not a fidelity guarantee, and once you measure both you find
the binding constraint is availability before it is per-field accuracy: a mapping that gets the class
right and the activity wrong is still ahead of three sources that ship no consumable mapping to grade in
the first place. These figures ride with that library commit, so re-run on a newer release before
repeating them. The mapping-fidelity bench is published on the lab,
and the coverage-before-fidelity finding is the kind of mapping evidence that feeds a vendor's
Capability Matrix score.
Scan-in-place
The scan-in-place objection deserves a straight answer.
There is a respectable argument that all of this is wasted effort, and it comes from the scan-in-place camp, of which scanner.dev is the cleanest expression: skip normalization and the lakehouse entirely, index your raw logs in S3, and scan them where they sit, because if mapping into OCSF is this expensive and this lossy, why pay for it at all.
The honest answer is that scan-in-place wins for search and loses for most of what depends on structure. When you want to hunt through a month of raw logs for an indicator, scanning the unstructured data in place is faster and cheaper than the pipeline it replaces, and the scan-in-place vendors are right about that, but correlation across sources, detection-as-code that has to reference a stable field, and any agent or model reasoning over security events all need the data to mean the same thing from one source to the next, which is the one thing raw logs do not do. When teams default to scan-in-place the reason is almost never that they have decided structure is worthless; it is that mapping into a structured schema is too hard, and that is a cost you can actually lower, so the cost of mapping sits right at the center of the architectural debate: bring it down and the structured side of the tradeoff becomes winnable, leave it where it is and scan-in-place keeps winning by default.
Where adoption dies
The on-ramp is expert-gated, and that is the bottleneck.
Which brings me back to where adoption dies. The community that produces OCSF skews toward standards authors and research-grade contributors, while the population that has to consume it is detection engineers and SOC teams who do not have a schema maintainer's fluency and should not need one, and because there is no accessible, validated, open library of mappings to start from, vendor after vendor and most large SOCs rebuild the same source-to-OCSF mappings privately, each paying the expensive part over again and sharing none of it. The expert-gating is the real bottleneck, and it stays invisible because each team pays it alone. It is the same bottleneck I described in the field-mapping anti-pattern, seen from the standard's side rather than the project plan's.
Six crosswalks do not fix that, but they do show the shape of the fix, because the mapping work turns out to be legible: it reduces to a small, nameable set of seams, much the same handful each time and most of them OCSF's own rather than any source's, it is validatable against the published schema and against real mapper output, and it does not require anyone's product, since the durable assets are the validated mappings, an OCSF validator, and a set of fixtures, none of which a vendor needs to own. The version of this that matters is open and neutral, governed where the standard is governed, so that the canonical mapping library belongs to the community rather than to any one vendor's lead-gen, which is why I built the Zeek mapping the way I did — open source, running at the sensor, validated on real traffic, contributed rather than held — and the other five crosswalks are the same bet in paper form, with the field-centric matrix as the single page that makes the whole thing legible to someone weighing whether OCSF is worth the cost.
That cost is real, and pretending otherwise is how standards lose credibility with the practitioners they need, so the honest pitch is the narrower and more durable one: the hard part of OCSF is the mapping, that mapping is a finite and nameable problem rather than an open-ended one, and the seams that remain are mostly the standard's own to close. The certificate class is missing, the disposition field is absent on exactly the classes where the telemetry is densest, and the severity contract asks for a judgment most sources never made, so naming those and mapping around them in the open is what lets the on-ramp get a little less expert-gated for the next team, which is, in the end, the kind of schema adoption that has actually tended to stick.